ELK
ELK 指的时 ElasticSearch + logstash + kibana
其中 es 和 kibana 的版本号必须对应。
在学习的时候,使用的时 es 7.6.2 和 kibana 7.6.2
ELK:搜索,日志分析,指标监控,信息安全等。
Beats + Logstash + ElasticSearch + Kibana
日志收集系统
- 收集
- 传输
- 存储
- 分析
- 警告
架构图
本地文件 + Logstash + ElasticSearch + Kibana
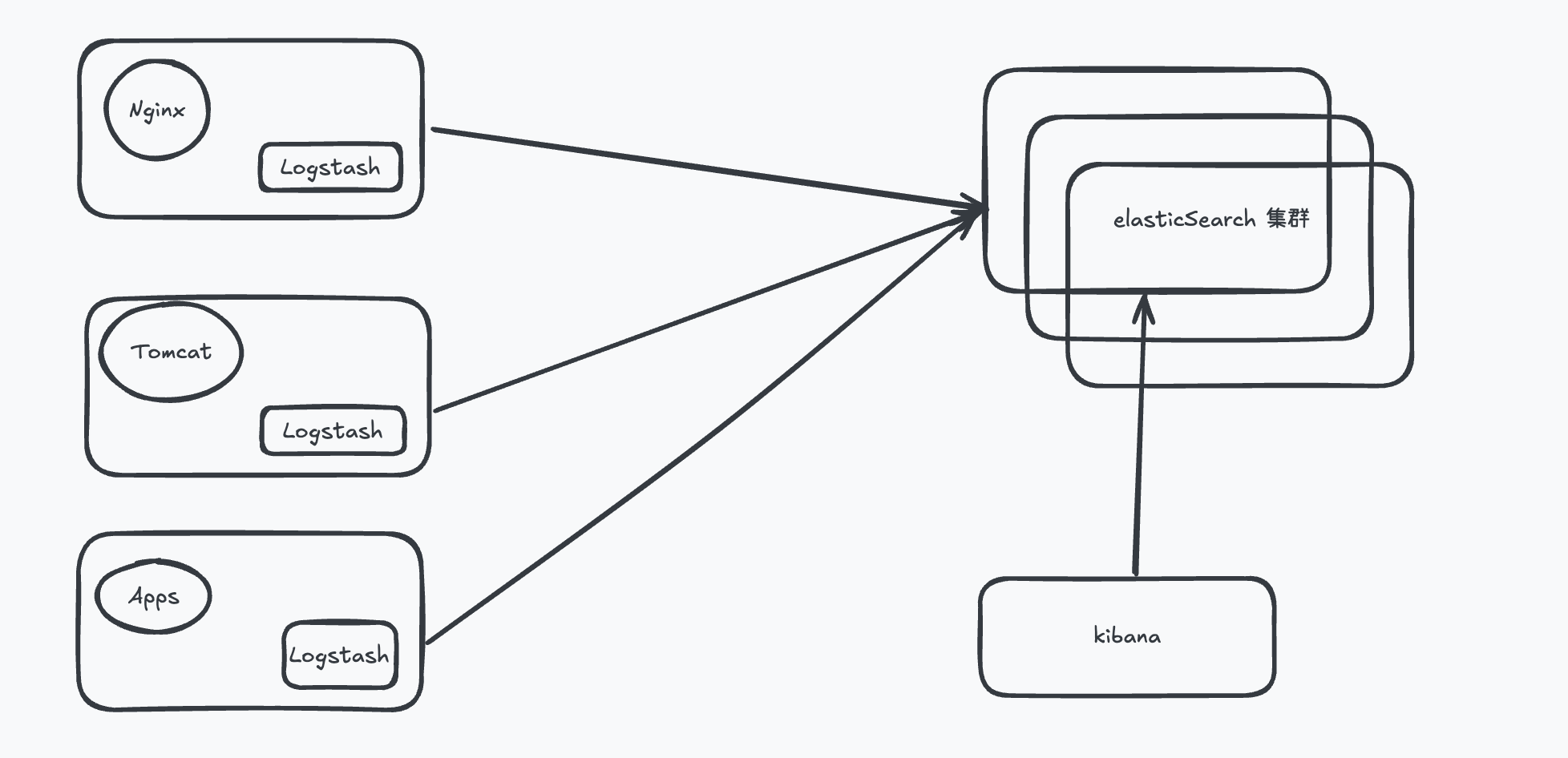
本地文件 + Filebeat+ Logstash + elasticSearch + Kibana
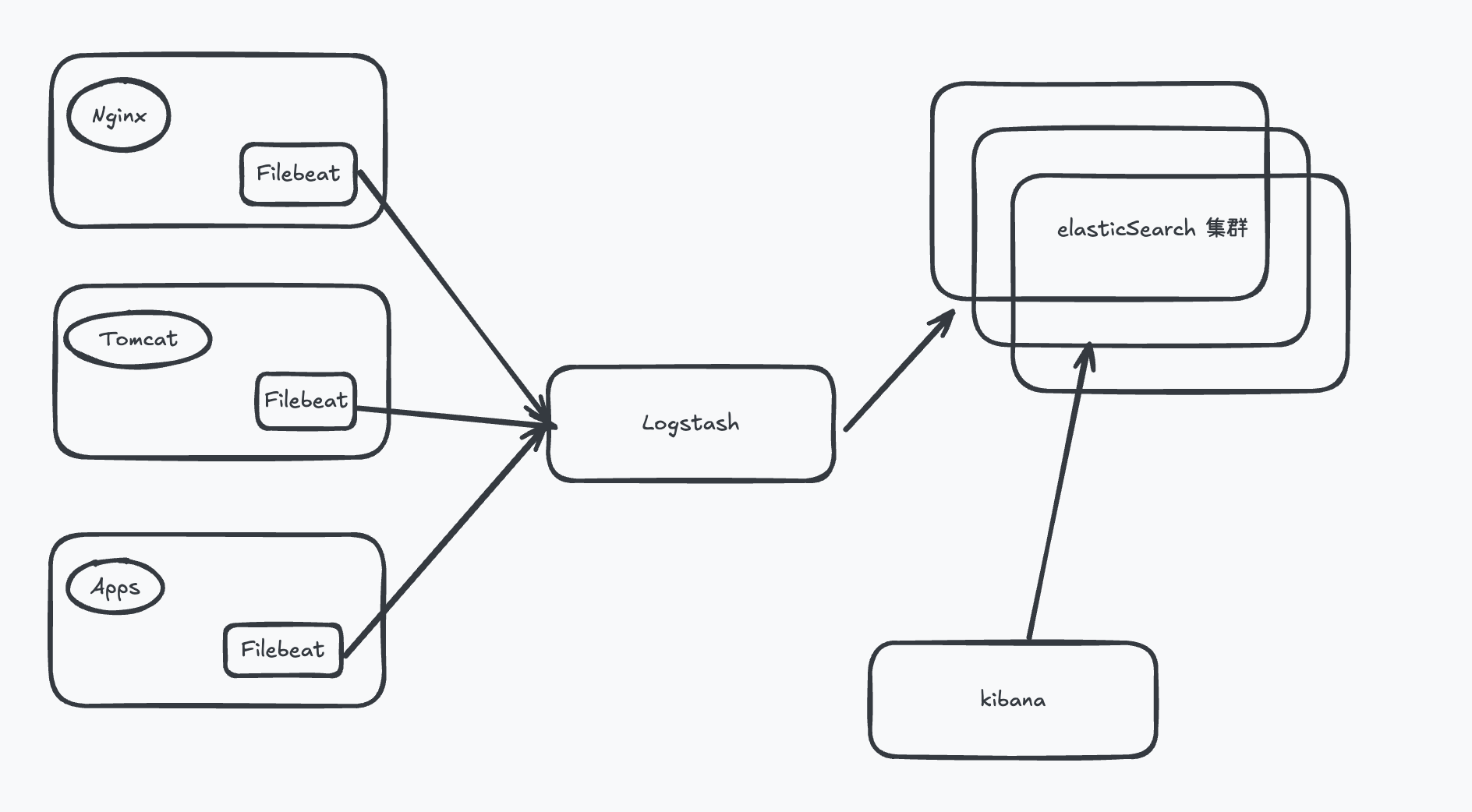
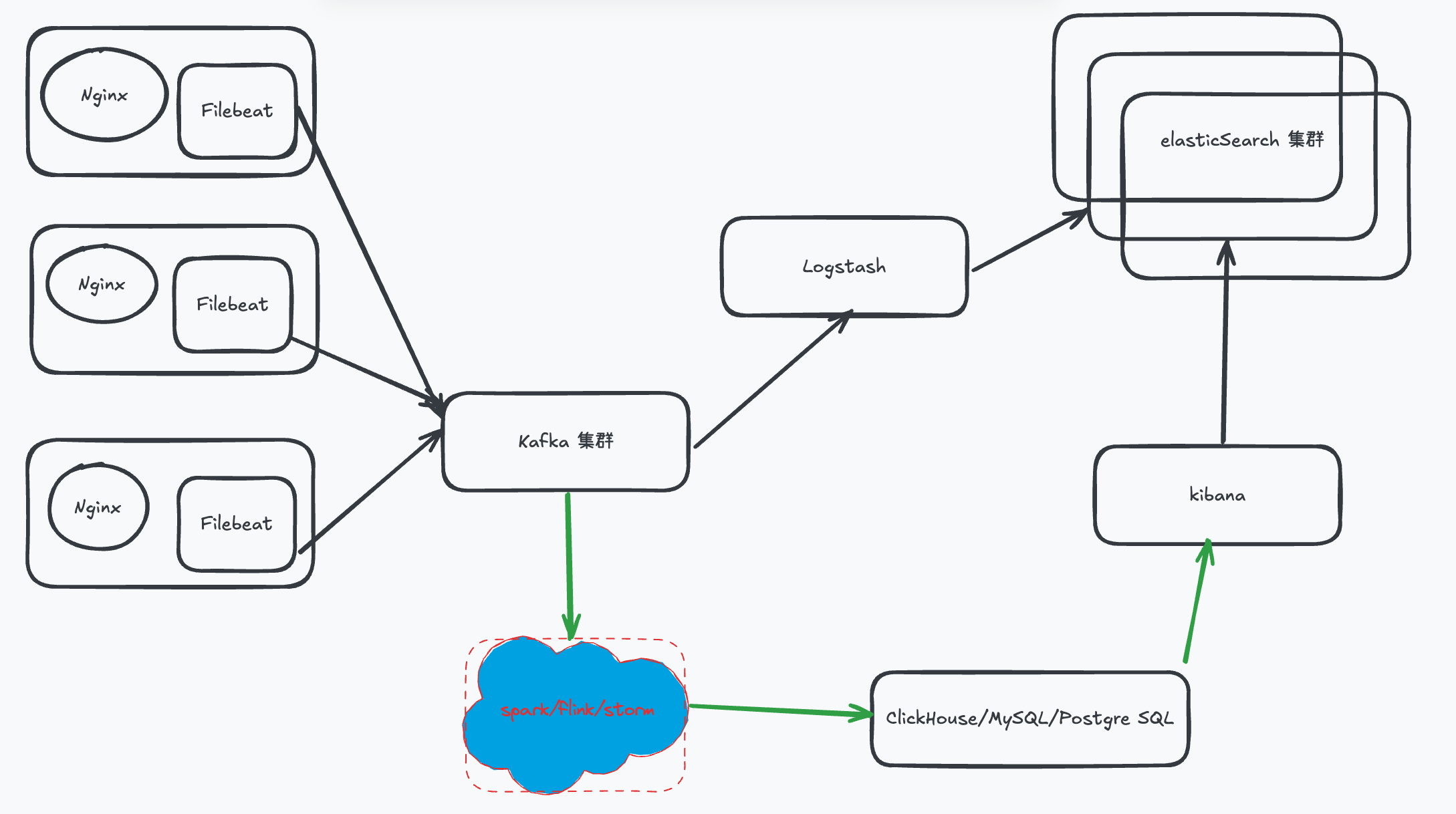
本地文件 + Filebeat + kafka + Logstash + elasticSearch + kibana + others
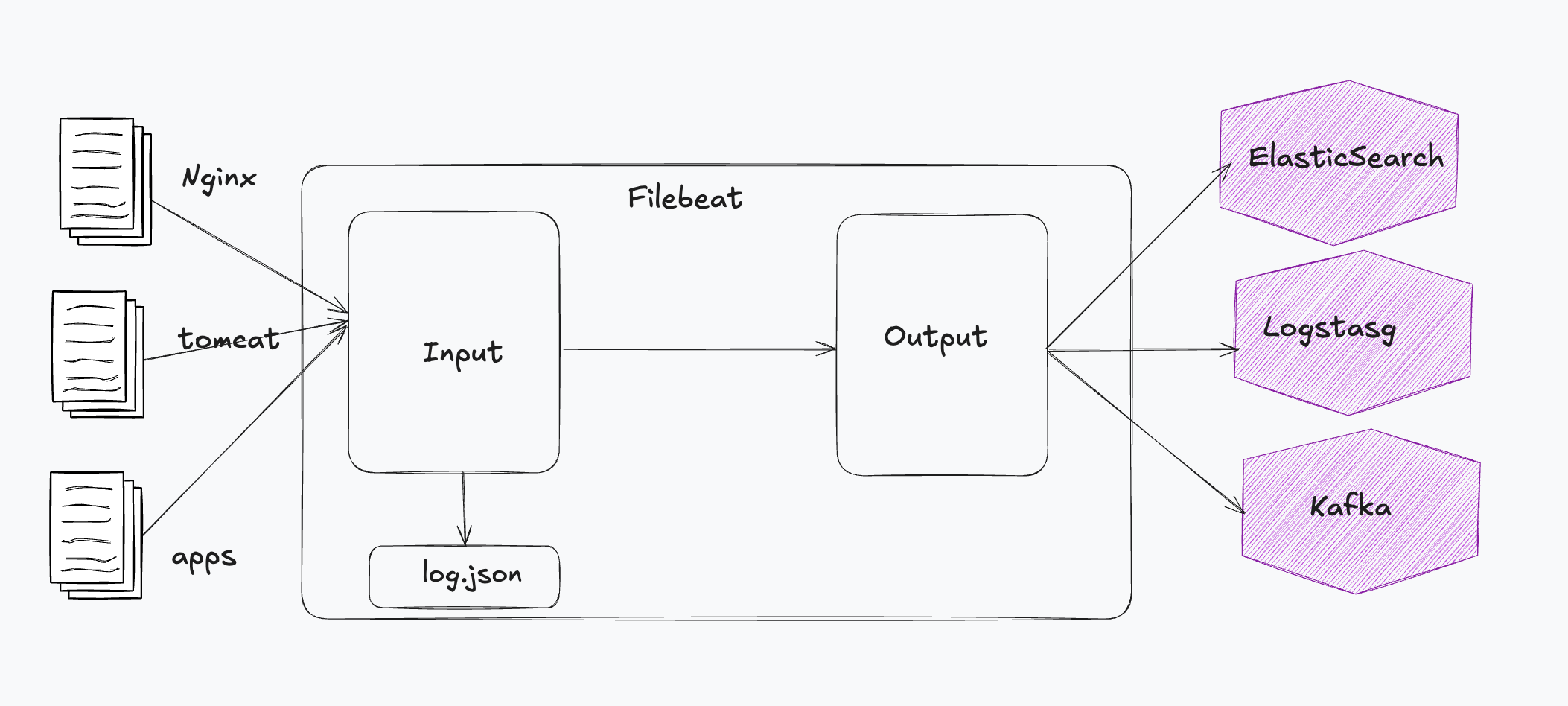
Beats
轻量型采集器。向 Logstash、ElasticSearch 发送数据。
- Filebeat
- Packetbeat
- Winlogbeat
- Metricbeat
- Heartbeat
- Auditbeat
- Fucntionbeat
- Journalbeat
FileBeat
filebeat.inputs:
- type: filestream
id: my-filestream-id
paths:
- /var/log/messages # 读取指定文件
- /var/log/*.log
将日志输出到终端

自定义字段和 Tags
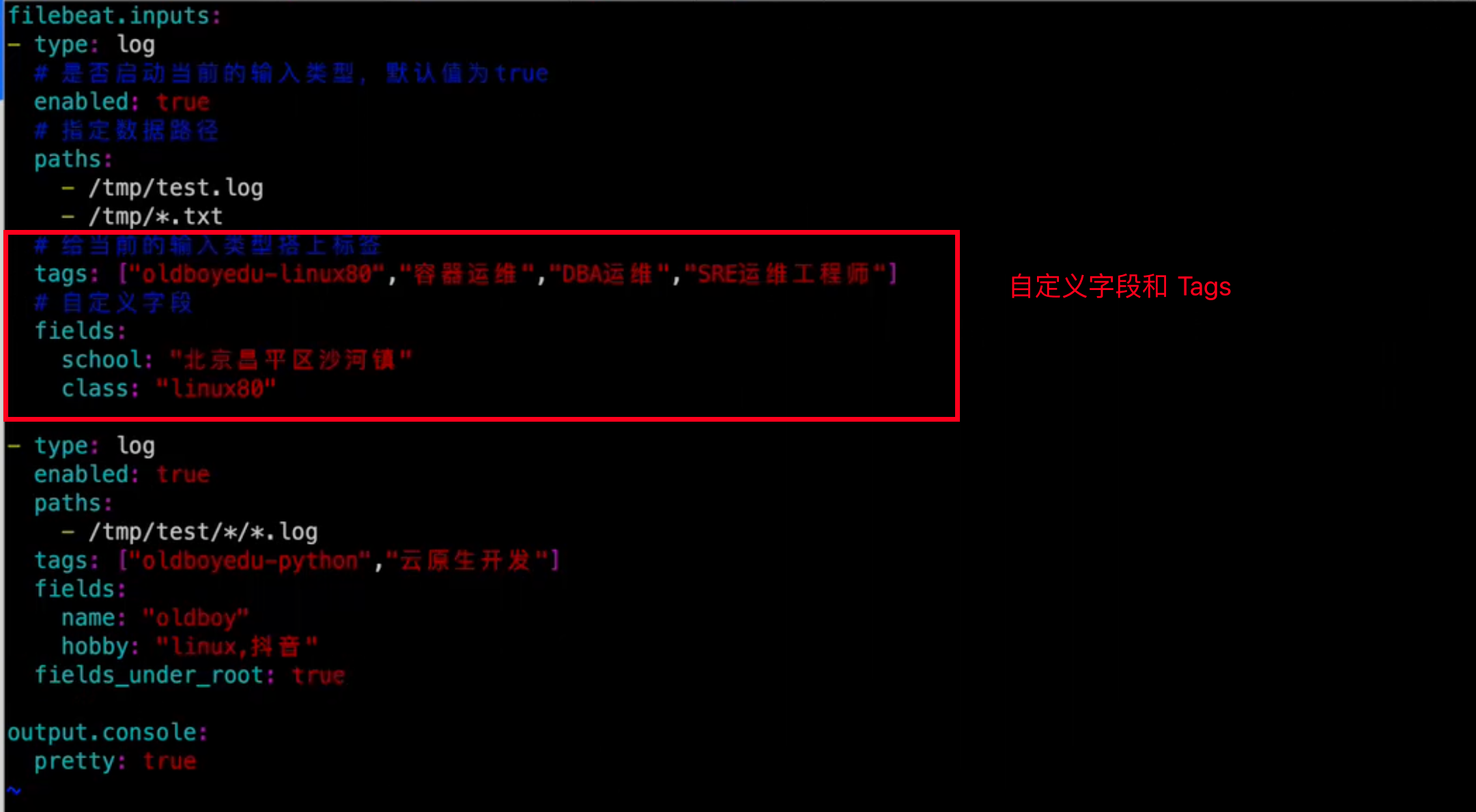
输出到 ES
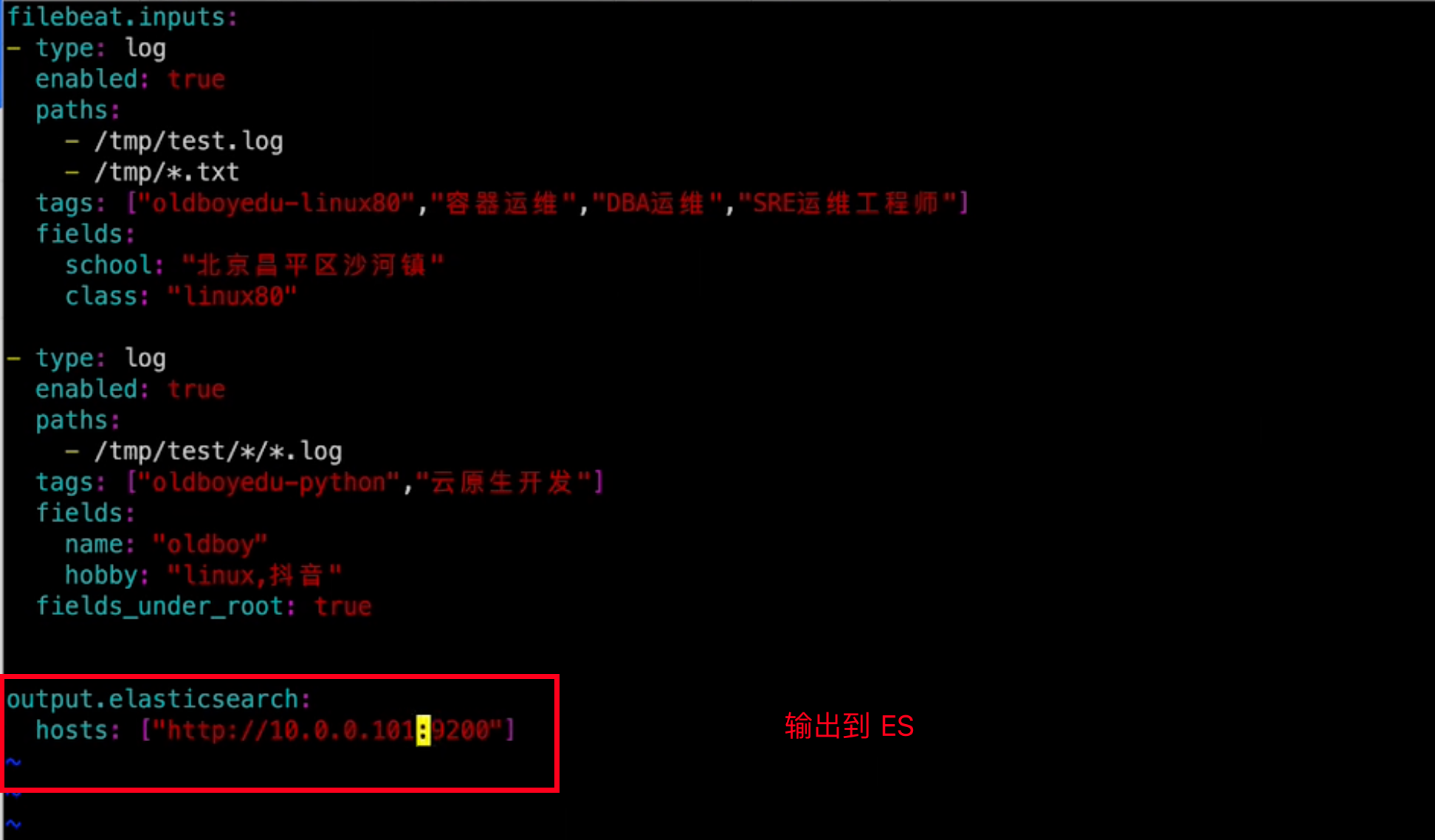
output.elasticsearch:
hosts: ["http://localhost:9200"]
index: "filebeat-%{[agent.version]}-%{+yyyy.MM.dd}"
setup.template.enabled: true
setup.template.name: "filebeat"
# 设置索引模板的匹配模式
setup.template.pattern: "filebeat*"
根据匹配到的 tags 写入不同的索引
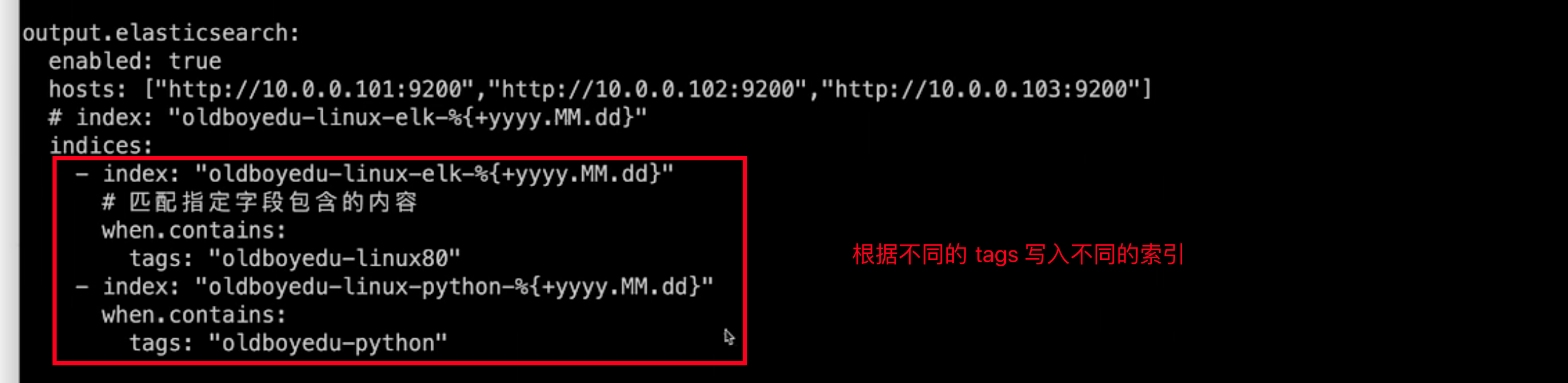
setup.template.name: "filebeat"
setup.template.fields: "fields.yml"
setup.template.overwrite: false
setup.template.settings:
index.number_of_shards: 1
index.number_of_replicas: 1
nginx 日志写入ES
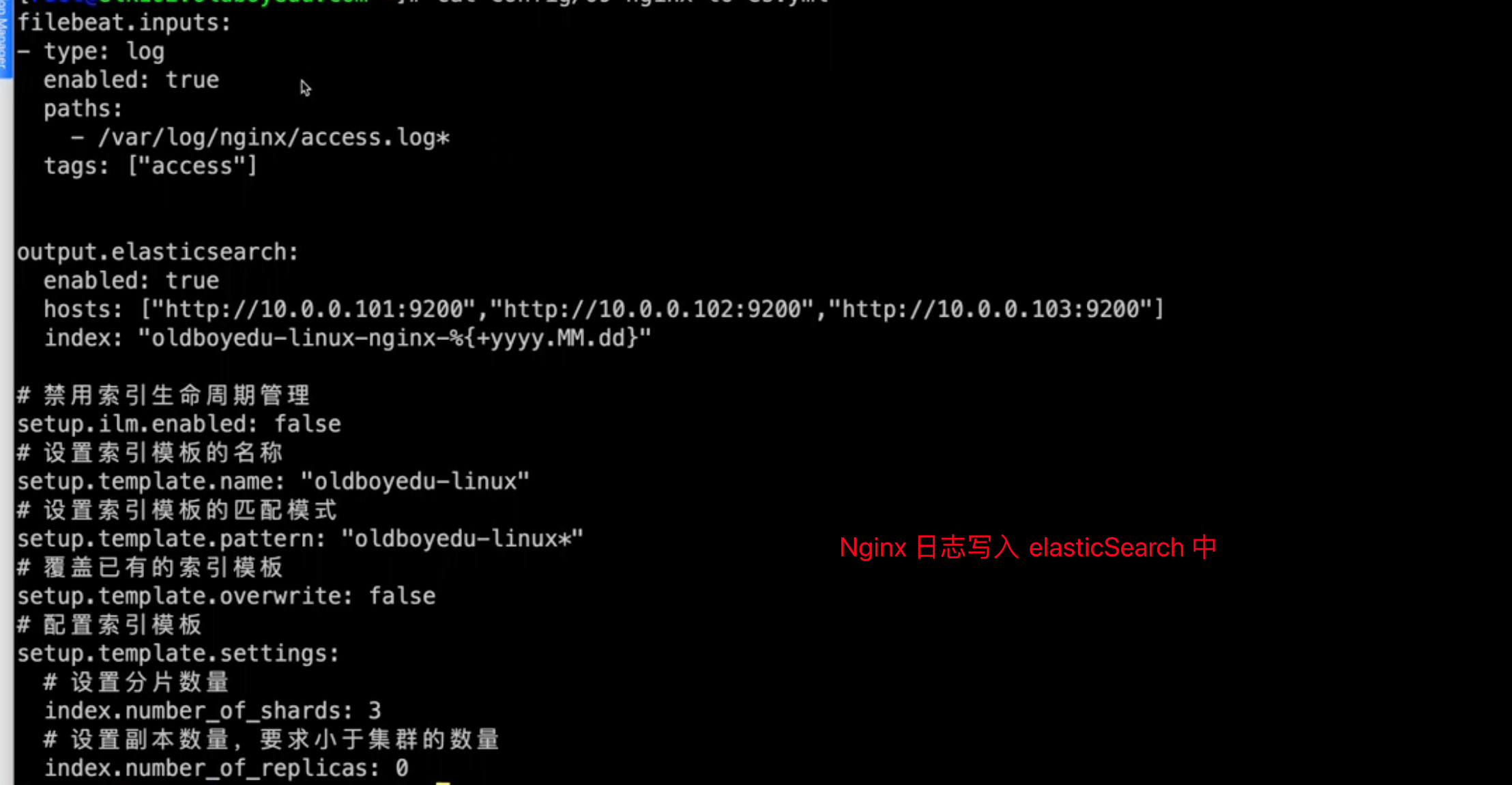
将日志调整为 json 格式的三种时机
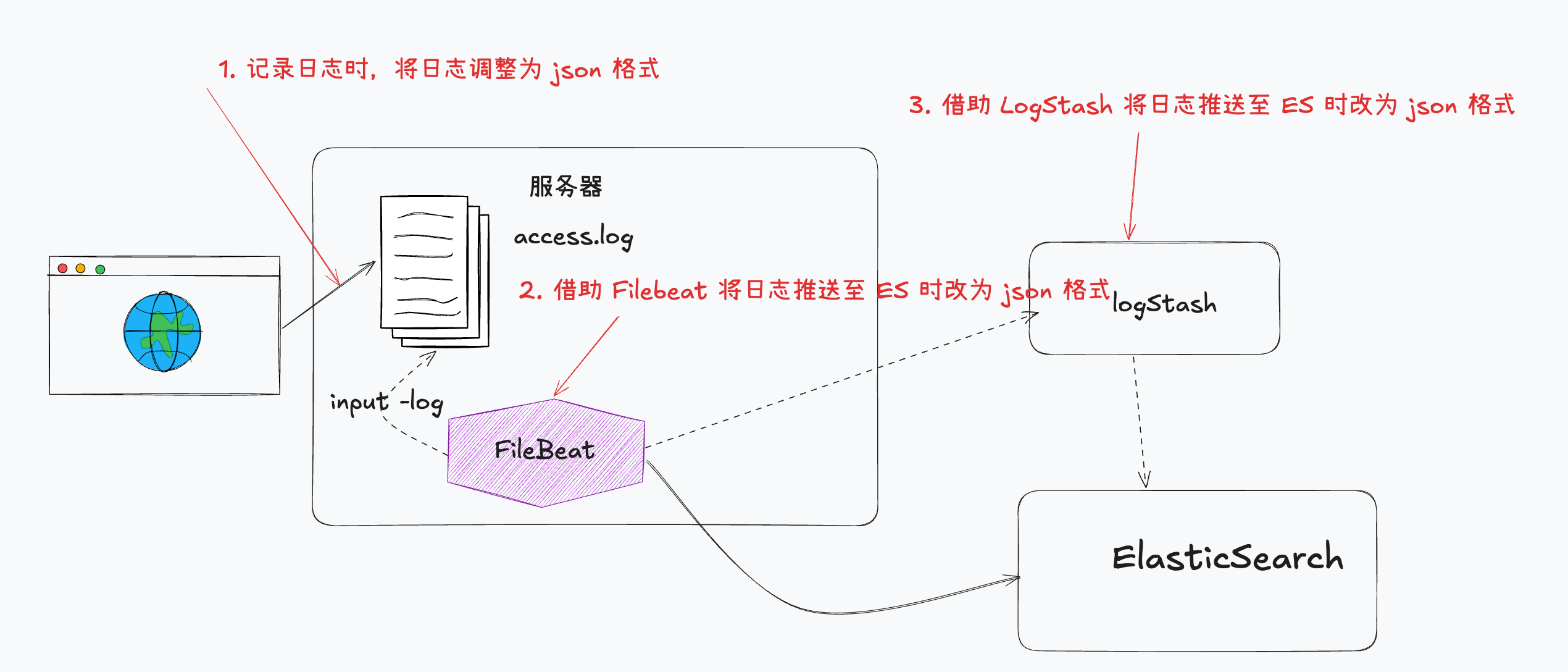
- 方案1 :修改 nginx 日志格式


- 方案 2: 使用 Filebeat 的 modules
# 查看列表
./filebeat modules list
# 启用 nginx 模块
./filebeat modules enable nginx
需要修改 #{FILEBEAT_HOME_PATH}/modules.d/nginx.yml 文件
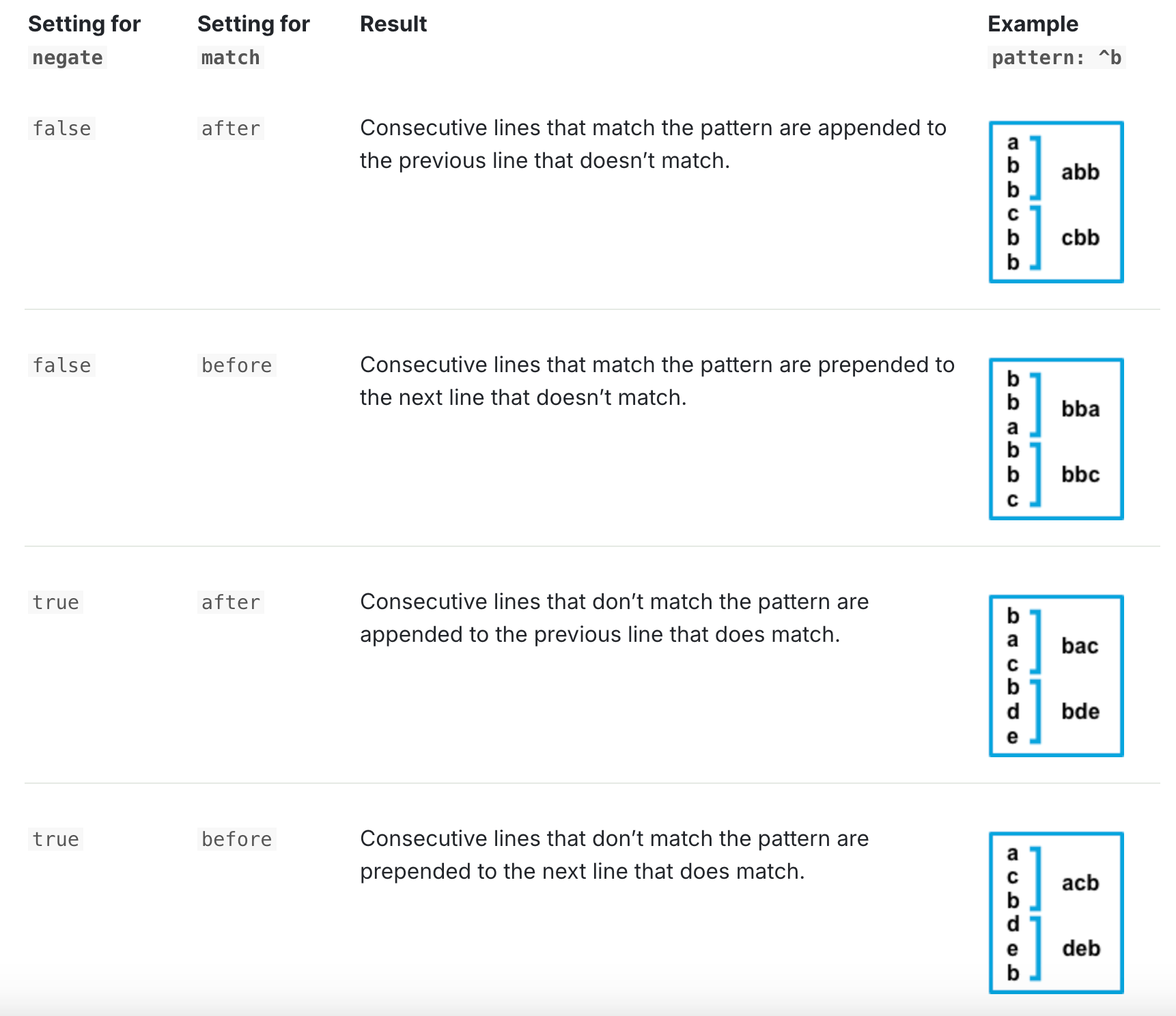
下面这段配置的作用是,将不以 [ 开头的行与前一个以 [ 开头的行合并。
parsers:
- multiline:
type: pattern
pattern: '^\['
negate: true # 定义模式是否被否定。
match: after # 指定 Filebeat 如何将匹配的行合并为一个事件。设置为 after 或 before 。这些设置的行为取决于您为 negate 指定的内容:
filebeat.inputs:
- type: log
...
exclude_lines: ['^DBG']
ElasticSearch
基于 Lucene 的分布式的全文搜索引擎。对外提供 RESTful web 接口。
Lucene 只适合在单机上使用。当数据量过大时,使用 ElasticSearch 。
全文检索、倒排索引
- 数据分布 分片机制
- 平行节点 内部交互
- 副本机制
- 高级搜索功能 count group by
实时搜索、稳定、可靠、快速、安装和使用方便。
- 全文检索
- 结构化搜索
- 分析
- 海量数据近实时处理
一、概念
- cluster 集群, 去中心化。
- Index 索引,直接存数据(document),一个索引是一个文档的集合。
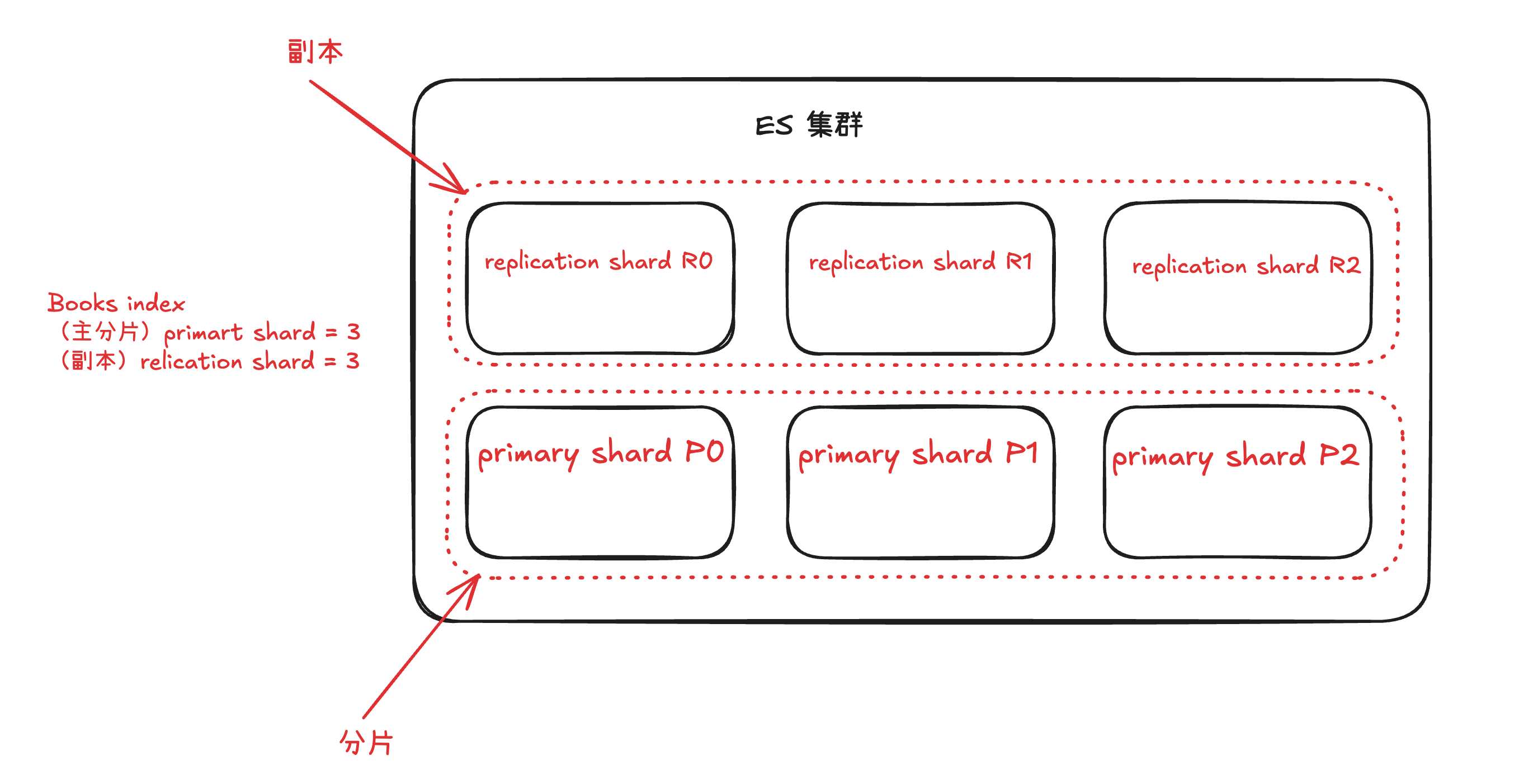
- shards 分片
- primary shard 主分片。一个完整的索引可以分成多个 primary shard 。存储在不同的 es 节点里。
- replica shard 主分片的副本,es 可以设置多个 replica shard。
- 提高系统的容错性,当某个节点某个 primary shard 损坏丢失时可以从副本中恢复
- 提高 es 的查询效率,es 会自动对搜索请求进行负载均衡,将并发的搜索请求发给合适的节点,增强并发处理能力。
- type es7 开始,没有 type
- document 文档,es 中的最小数据单元,一个 document 就是一条数据。一般使用 JSON。
- 元数据 在 es 中以 "_" 开头
7. 倒排索引 es搜索原理
对数据进行分析,抽取出数据中的词条,以词条为 key,对应数据的存储位置作为 value,实现索引的存储。这种索引成为倒排索引。倒排索引是
document写入es时分析维护的。 - Near Realtime NRT , 近实时。数据提交索引后,立马就可以搜索到。
- 近实时 NRT
near real-time数据库 database --> 索引 index
表 table --> 类型 type
行 row --> 文档 document
列 column --> 映射 mapping
表结构 schema --> 反向索引
SQL --> 查询 DSL
SELECT * FROM TABLE --> GET http://
UPDATE TABLE set --> PUT http://
DELETE --> DELETE http://
二、安装 ElasticSearch
docker 安装
- 下载镜像
docker pull elasticsearch:7.6.2
- 启动容器
--name 指定容器的名称
-d
-p 指定端口映射
--restart=always 设置开机启动
-e 指定参数
docker run --name=es -d -p 9200:9200 -p 9300:9300 --restart=always -e "discovery.type=single-node" elasticsearch:7.6.2
- 查看日志
docker logs -f es
- 启动成功
访问 http://localhost:9200 返回下面的 JSON 表示启动成功
{
"name" : "20eb9e1f5607",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "6Ac_kX6fRpaxcNIGSfO62Q",
"version" : {
"number" : "7.6.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
三、在 Kibana 中使用 ElasticSearch
1、查看健康状态
查看所有索引
GET _cat/indices
查看所有分片
GET _cat/shards
2、索引
创建索引
语法:
PUT 索引名{索引配置参数}
es 7 之前,默认分配 5 个 primary shard ,每个 primary shard 分配一个 replica shard。
es 7 之后,默认分配 1 个 primary shard ,每个 primary shard 分配一个 replica shard。
- 创建索引分片
PUT test_index_0
- 创建索引时指定分片
注意:不能把大括号放到索引名称的后,kibana hui把它当成索引名的一部分
PUT tset_index_1
{
"settings":{
"number_of_shards":2,
"number_of_replicas":1
}
}
修改索引
语法:
PUT 索引名/_settings{索引配置参数}
索引一旦创建,primary shard 数量不可变化,可以修改 replica shard 数量。
PUT index_test_1/_settings
{
"number_of_replicas":2
}
删除索引
语法: DELETE 索引名1,索引名2...
Document
新增 Document
如果要添加的 document 对应的 index 不存在,那么 es 会自动创建 index。
新增 document 有两种方式
- 不存在就新增,存在就更新
PUT index_test_1/_doc/1
{
"name":"wangzhy",
"address":"zhuhai"
}
- 强制新增,如果不存在则新增,存在就报错
PUT index_test_1/_create/2
{
"name":"wangzhy2",
"address":"zhuhai2"
}
- 自动生成id
# 虽然指定了 document 的id,但是还是会自动生产一个 id
POST index_test_1/_doc/1
{
"name":"wangzhy3",
"address":"zhuhai3"
}
POST index_test_1/_doc
{
"name":"wangzhy4",
"address":"zhuhai4"
}
查询 Document
单个查询
GET index_test_1/_doc/1
批量查询
GET index_test_1/_mget
{
"docs":[
{"_id":1},
{"_id":2}
]
}
更新 Document
> 语法:` POST 索引名/_update/唯一ID{doc:{字段名:字段值}}}`
>
> 只更新 Document 的部分字段,这种更新方式也是标记原有数据为 delete 状态,创建一个新的document 数据,将新的字段和未更新的原有字段组成新的 都document并创建。对比全量替换而言,只是操作上的方便,在底层执行上几乎没有区别。
POST index_test_1/_update/1
{
"doc":{
"count":1122
}
}
GET index_test_1/_doc/1
删除文档
es 删除文档时,会先将 document 标记为 delete 状态,而不是物理删除, 只有当 es 存储空间不足或工作空闲时,才会执行物理删除操作。 标记为 delete 状态的数据不会被查询搜索到。
语法: DELETE 索引名/_doc/唯一ID
GET index_test_1/_doc/G1OI_Y0BF9RaHrJrhsS5
DELETE index_test_1/_doc/G1OI_Y0BF9RaHrJrhsS5
bulk 批量增删改(重点记忆)
> POST _bulk
> {"action_type":{"metadata_name":"metadata_value"}}
> {document datas|action datas}
action_type
- create 强制创建,相当于 PUT 索引名/_create/唯一id/_create id 必须有
- index 普通的 post 操作,相当于创建 document 或全量替换
- update 更新操作 partial update,相当于 POST 索引名/_update/唯一ID/_update
- delete 删除操作
格式必须是下面这样。
POST _bulk
# 创建一个 doc
{"create":{"_index":"index_test_1","_id":"5"}}
{"name":"wangzhy5","address":"adress5"}
# 创建或全量替换
{"index":{"_index":"index_test_1","_id":6}}
{"name":"wangzhy6","address":"adress6"}
# 更新 doc
{"update":{"_index":"index_test_1","_id":6}}
{"doc":{"address":"address666666"}}
# 删除一个 doc
{"delete":{"_index":"index_test_1","_id":6}}
四、分词器 analyzer 和 标准化处理 normalization
1、分词器
- standard analyzer 默认的分词器,标准分词器,处理英语语法的分词器。
- simple analyzer 简单分词器
- whitesapce analyzer 空白分词器
- language analyzer 语言分词器
GET _analyze
{
"text":"I am a Chinese!",
"analyzer":"standard"
}
GET _analyze
{
"text":"我是中国人!",
"analyzer":"standard"
}
2、基于 Docker 安装中文分词器
1、 进入 Docker 容器内部
docker exec -it es /bin/bash
2、执行命令
./bin/elasticsearch-plugin install https://github.com/infinilabs/analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
3、重启 es 容器
docker restart es
3、IK 分词器
- ik_max_word 最细粒度的拆分
- ik_smart 最粗粒度的拆分
GET _analyze
{
"text":"我是中国人!",
"analyzer":"ik_max_word"
}
GET _analyze
{
"text":"我是中国人!",
"analyzer":"ik_smart"
}
自定义词典
1、将 es 容器中指定文件夹拷贝到当前目录
docker cp es:/usr/share/elasticsearch/config/analysis-ik .
2、通过编辑器修改 main.dic 文件
为什么直接在容器中�修改呢? 因为通过 vi 修改 main.dic 会出现乱码
每一行就是一个词语。
3、将修改的文件复制到容器里
docker /usr/local/es/analysis-ik/main.dic cp es:/usr/share/elasticsearch/config/analysis-ik
4、检查修改是否成功并重启容器
mapping 问题
- 类型必须记住
- text 和 keyword 的区别
- mapping 生效后不允许修改。所以创建索引时直接指定 mapping 关系。
为什么要学习 mapping?
如果没有 mapping 所有 text 类型属性默认都使用 standard 分词器。所以如果希望使用 ik 分词器,就必须配置自定义 mapping。
1、mapping 核心数据类型
只有 text 类型才能被分词。其他类型不允许。
- 文本 text
- 整数:byte short integer long
- 浮点数 float double
- 布尔类型 boolean
- 日期类型 date
- 数组类型
array {a:[]} - 对象类型
object {a:{}} - 不分词的字符串 keyword
2、创建索引时指定 mapping
PUT index_test_2
{
"mappings" : {
"properties" : {
"name" : {
"type" : "keyword"
},
"age" : {
"type" : "integer"
},
"desc" : {
"type" : "text",
"analyzer":"ik_max_word"
}
}
}
}
}
3、为已有索引添加新的字段 mapping
PUT index_test_2/_mapping
{
"properties" : {
"address" : {
"type" : "text",
"analyzer":"ik_smart"
}
}
}
}
4、测试字段分词结果
PUT index_test_2/_doc/1
{
"name":"张三",
"age":20,
"desc":"我是中国人",
"address":"中国"
}
GET index_test_2/_analyze
{
"field":"address",
"text": "张三"
}
GET _analyze
{
"text":"我是中国人!",
"analyzer":"ik_smart"
}
五、搜索
构建测试数据
PUT test_search
{
"mappings": {
"properties":{
"dname":{
"type":"text",
"analyzer":"standard"
},
"ename":{
"type":"text",
"analyzer":"standard"
},
"eage":{
"type":"long"
},
"hiredate":{
"type":"date"
},
"gender": {
"type":"keyword"
}
}
}
}
POST test_search/_bulk
{"index": {}}
{"dbname": "Sales Department","ename": "张三","eage": 20,"hiredate": "2019-01-01","gender": "男性"}
{"index": {}}
{"dbname": "Sales Department","ename": "李四","eage": 21,"hiredate": "2019-02-01","gender": "男性"}
{"index": {}}
{"dbname": "Sales Department","ename": "王五","eage": 23,"hiredate": "2019-01-03","gender": "男性"}
{"index": {}}
{"dbname": "Sales Department","ename": "赵六","eage": 26,"hiredate": "2018-01-01","gender": "男性"}
{"index": {}}
{"dbname": "Sales Department","ename": "韩梅梅","eage": 24,"hiredate": "2019-03-01","gender": "女性"}
{"index": {}}
{"dbname": "Sales Department","ename": "钱虹","eage": 29,"hiredate": "2018-03-01","gender": "女性"}
query DSL
请求参数是请求体传递的。 在 es 中请求体字符集默认为 UTF-8
> GET 索引名/_search
> {
> "command":{"parameter_name":"parameter_value"}
> }
1、查询所有数据
GET 索引名/_search
{
"query":{"match_all":{}}
}
GET test_search/_search
{
"query":{"match_all":{}}
}
2、match search
GET test_search/_search
{
"query":{
"match":{
"ename":"张三"
}
}
}
3、phrase search
短语检索。要求查询条件必须和具体数据完全匹配才算搜索结果。
- 对搜索条件进行拆词
- 把拆词当作一个整体,整体去索引中匹配,就必须严格匹配才能查询到。
GET test_search/_search
{
"query":{
"match_phrase":{
"ename":"张三"
}
}
}
POST test_search/_bulk
{"index": {}}
{"dbname": "Sales Department","ename": "张三李","eage": 20,"hiredate": "2019-01-01","gender": "男性"}
{"index": {}}
{"dbname": "Sales Department","ename": "李张三","eage": 20,"hiredate": "2019-01-01","gender": "男性"}
POST test_search/_bulk
{"index": {}}
{"dbname": "Sales Department","ename": "张李三","eage": 20,"hiredate": "2019-01-01","gender": "男性"}
4、range
GET test_search/_search
{
"query":{
"range":{
"eage":{
"gte":10,
"lte":20
}
}
}
}
5、多条件复合查询
GET test_search/_search
{
"query": {
"bool": {
"should": [
{
"bool": {
"must": [
{
"match": {
"ename": "钱虹"
}
},
{
"match": {
"eage": 29
}
}
]
}
},
{
"bool": {
"must": [
{
"match": {
"ename": "韩梅梅"
}
},
{
"match": {
"eage": 24
}
}
]
}
}
]
}
}
}
6、排序、分页
GET test_search/_search
{
"query": {
"match_all":{}
},
"sort":{
"eage":{
"order":"desc"
}
}
}
GET test_search/_search
{
"query": {
"match_all":{}
},
"sort":{
"eage":{
"order":"desc"
}
},
"from":0,
"size":2
}
7.highlight search
GET test_search/_search
{
"query": {
"match":{
"ename": "三"
}
},
"highlight" : {
"fields": {
"ename":{
"fragment_size": 5,
"number_of_fragments": 1
}
},
"pre_tags" : ["<em>"],
"post_tags" : ["</em>"]
}
}
六、Java 操作 elasticsearch
- elasticsearch 提供的客户端 API
注意:版本要与 elasticsearch 的版本一致
<!-- https://mvnrepository.com/artifact/org.elasticsearch.client/transport -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>7.6.2</version>
</dependency>
- spring data elasticsearch
更简单方便
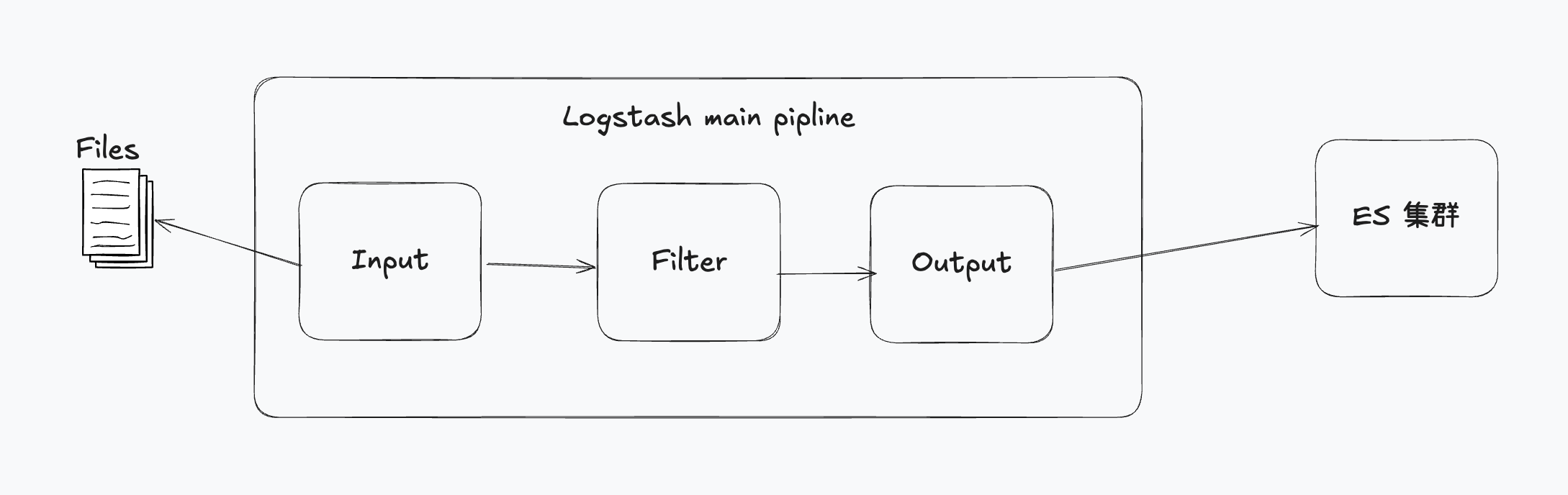
LogStash
动态数据收集管道。集中管理日志
input -> filter -> output
直接指定配置
./logstash -e "input { stdin { } } output { stdout {} }"
收集本地文件

日志聚合
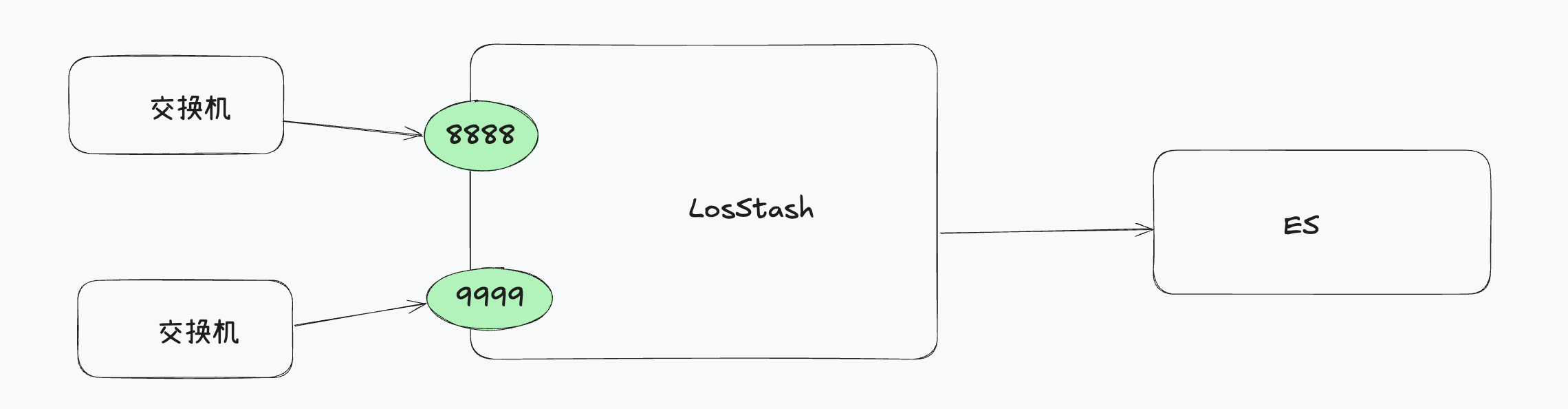
基于 HTTP

Logstash 对接 Redis
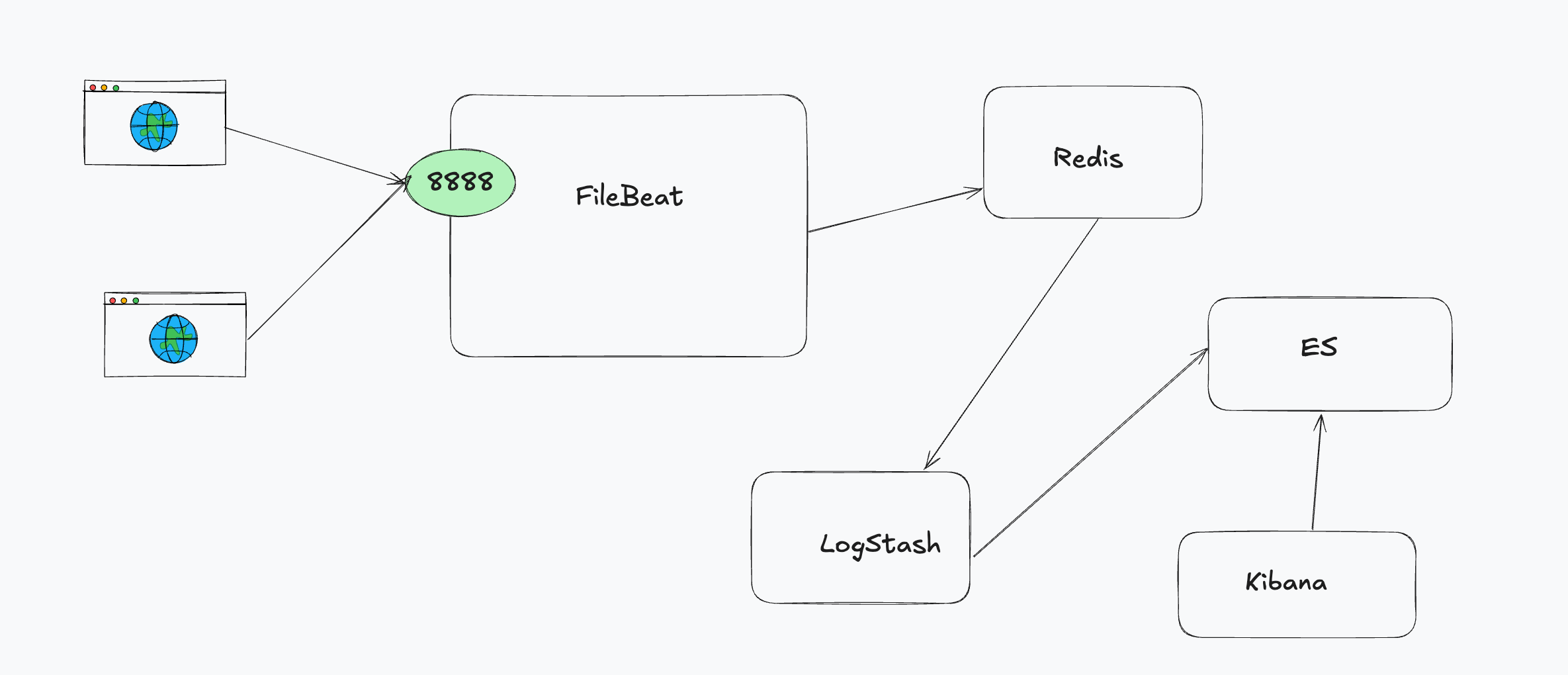
LogStash + Filebeat

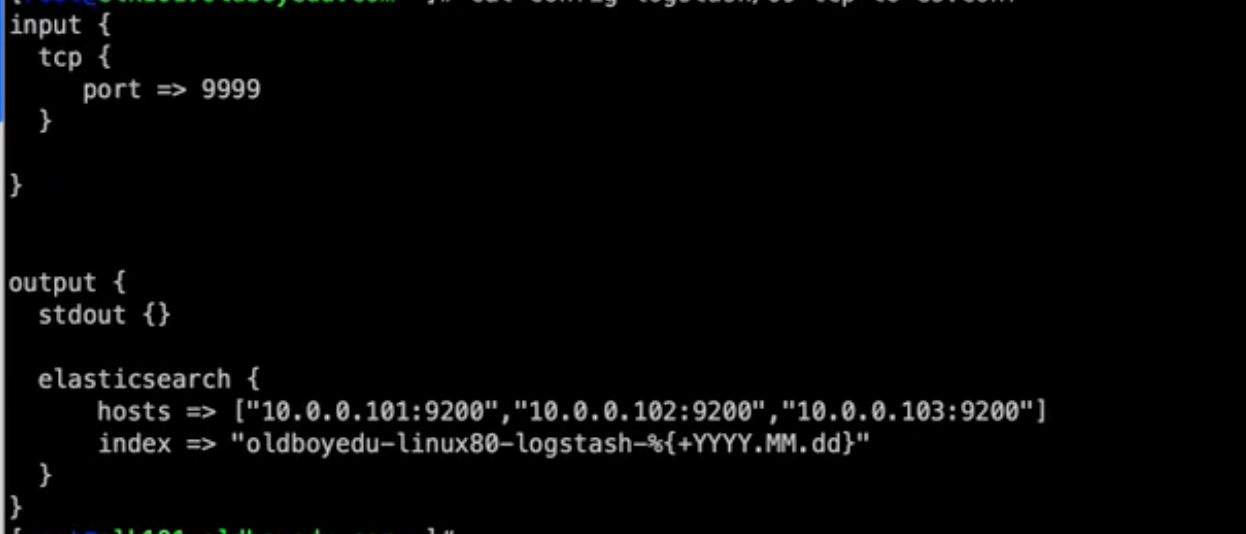
LosStash 输出到 ES
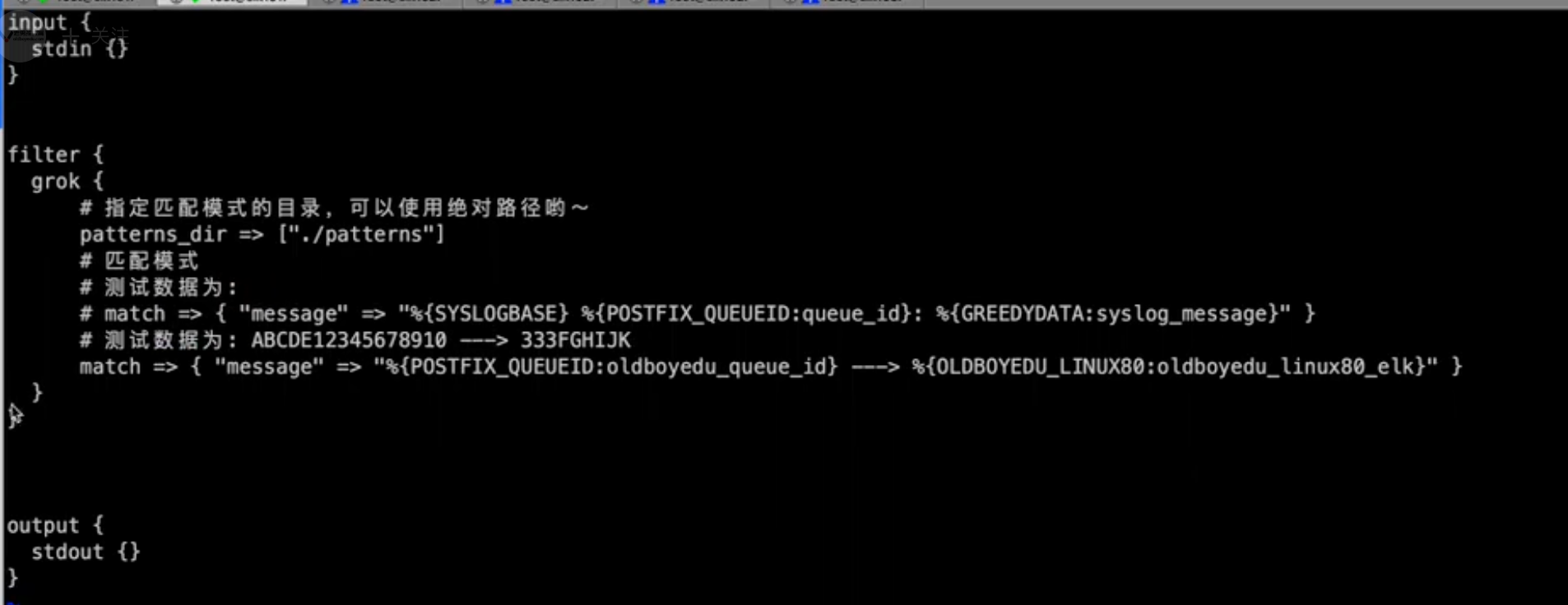
grok 插件使用
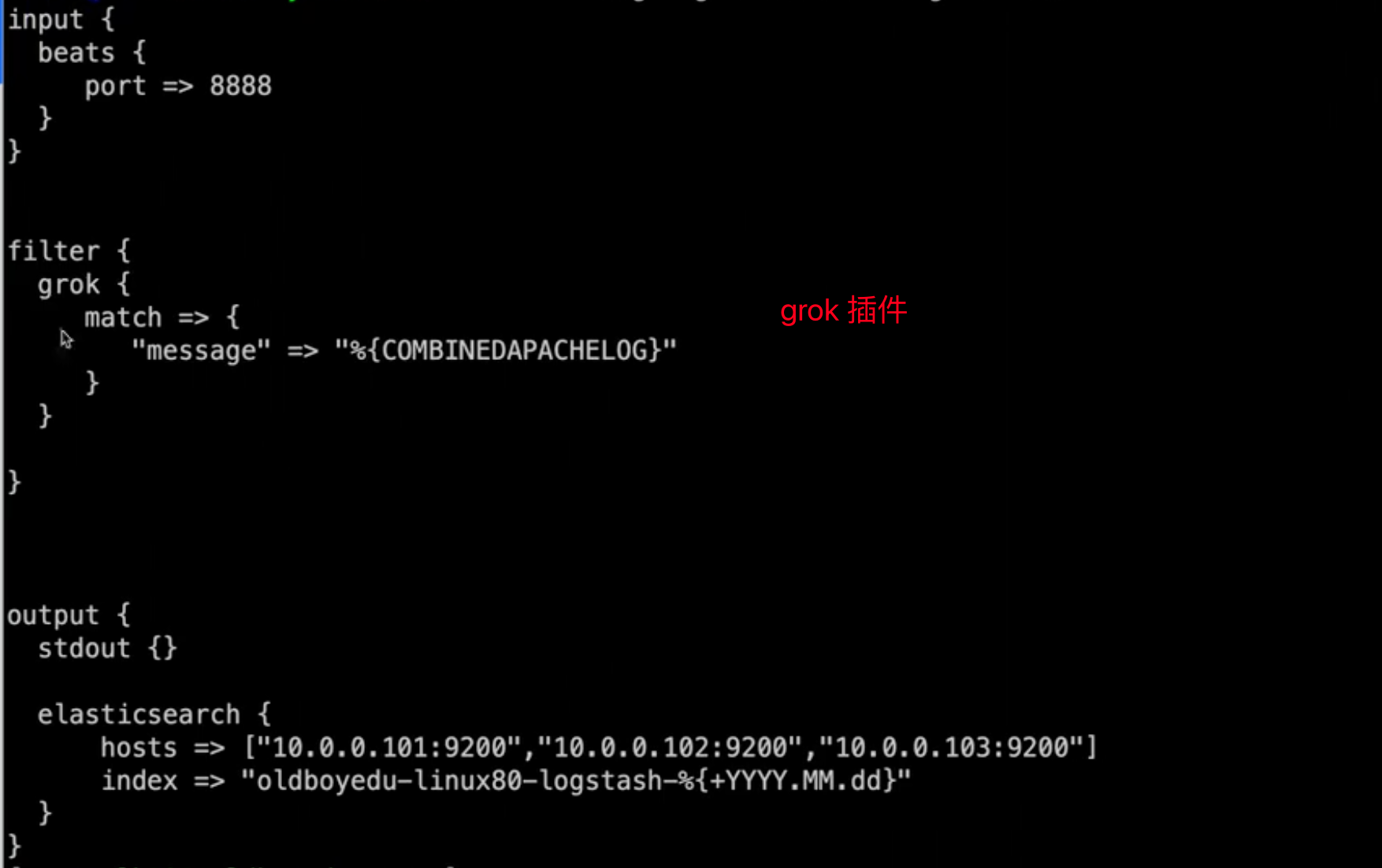
自定义 grok配置
grok 插件添加移除字段、tag
