哈希一致性算法
一个分布式 KV 缓存系统,某个 key 应该到哪个或者哪些节点上获得,应该是确定的,不是说任意访问一个节点都可以得到缓存结果的。
哈希取模
对缓存的 key 进行 hash 函数,得到 hashcode,然后根据节点的数量进行取模,得到最终存取数据的节点。

哈希取模算法的缺点
在增删节点时,最坏的情况是整个集群的缓存重新计算!!!
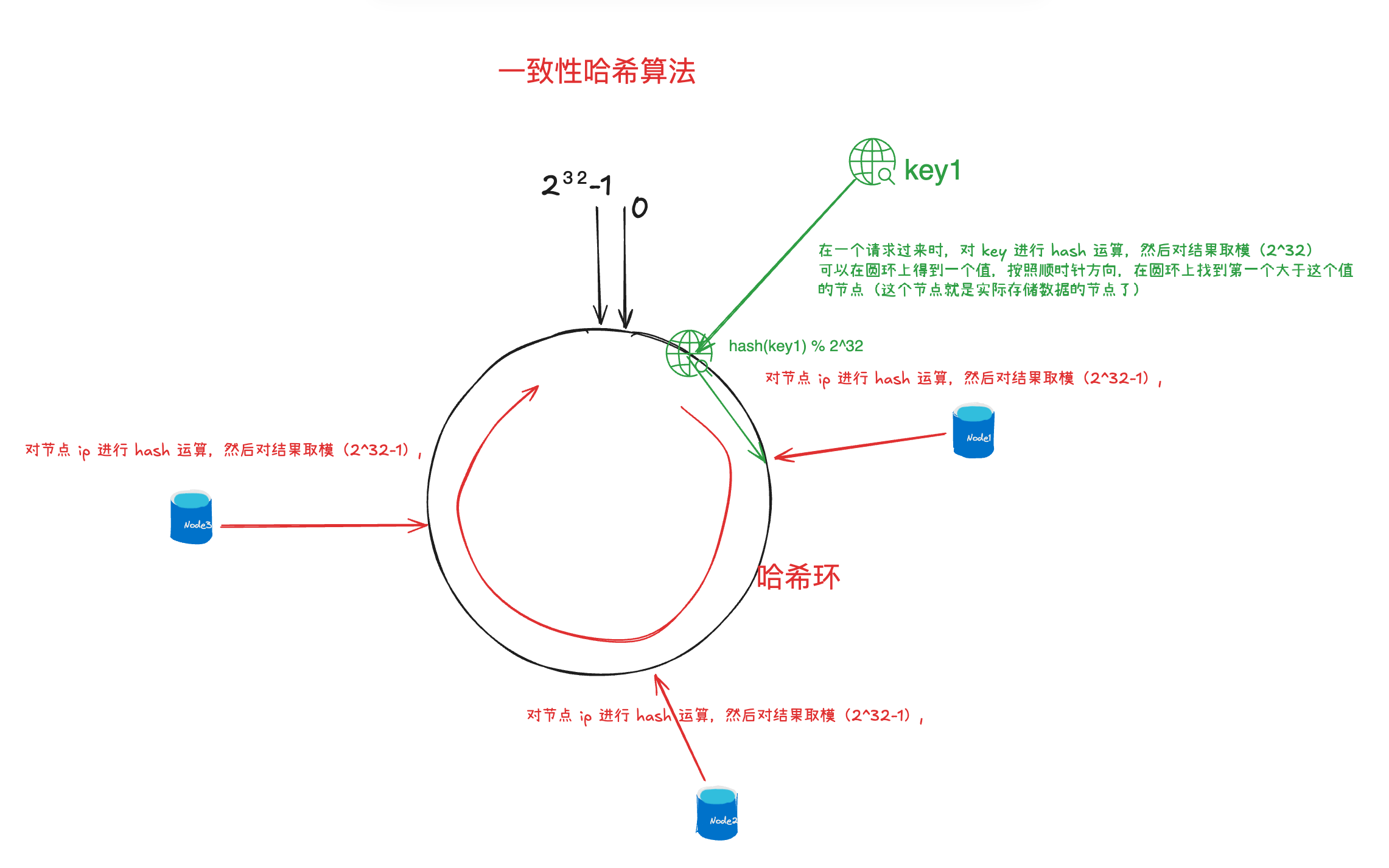
一致性哈希算法
其算法的工作原理如下:
- 一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环,整个哈希空间的取值范围为0~2^32-1;
- 计算各服务器节点的哈希值,并映射到哈希环上;
- 将服务发来的数据请求使用哈希算法算出对应的哈希值;
- 将计算的哈希值映射到哈希环上,同时沿圆环顺时针方向查找,遇到的第一台服务器就是所对应的处理请求服务器。
- 当增加或者删除一台服务器时,受影响的数据仅仅是新添加或删除的服务器到其环空间中前一台的服务器(也就是顺着逆时针方向遇到的第一台服务器)之间的数据,其他都不会受到影响。
一致性哈希算法新增节点

一致性哈希算法的缺点
- 数据不均匀,可以通过给每个机器增加多个虚拟节点来实现均匀分布(数据倾斜)
- 在增删节点的时候,一致性哈希可以避免数据的全量迁移,但还是不能杜绝数据迁移的情况。(需要迁移的只是改变的节点和它的上游节点的数据)