分布式
分布式概念
1.解释一下什么是 CAP ?
- Consistency:一致性就是在客户端任何时候看到各节点的数据都是一致的。
- Availability:可用性就是在任何时刻都可以提供读写。
- Partition Tolerance:分区容错性是在网络故障、某些节点不能通信的时候系统仍能继续工作。
具体地讲在分布式系统中,在任何数据库设计中,一个Web应用最多只能同时支持上面的两个属性。显然,任何横向扩展策略都要依赖于数据分区。因此,设计人员必须在一致性与可用性之间做出选择。
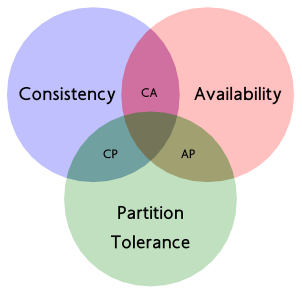
AP(高可用&&分区容错):
允许至少一个节点更新状态会导致数据不一致,即丧失了C性质(一致性)。会导致全局的数据不一致。
CP(一致&&分区容错):
为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质(可用性)。分区同步会导致同步时间无限延长(也就是等数据同步完成之后才能正常访问)
CA(一致&&高可用):
两个节点可以互相通信,才能既保证C(一致性)又保证A(可用性),这又会导致丧失P性质(分区容错性)。这样的话就分布式节点受阻,无法部署子节点,放弃了分布式系统的可扩展性。因为分布式系统与单机系统不同,它涉及到多节点间的通讯和交互,节点间的分区故障是必然发生的,所以在分布式系统中分区容错性是必须要考虑的。
2.什么分布式事务?
分布式事务服务(Distributed Transaction Service,DTS)是一个分布式事务框架,用来保障在大规模分布式环境下事务的最终一致性。
CAP理论告诉我们在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出��现延迟丢包等问题,所以分区容忍性是我们必须需要实现的,所以我们只能在一致性和可用性之间进行权衡。
为了保障系统的可用性,互联网系统大多将强一致性需求转换成最终一致性的需求,并通过系统执行幂等性的保证,保证数据的最终一致性。
3.了解BASE理论吗?
BASE理论指的是:
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性) BASE理论是对CAP中的一致性和可用性进行一个权衡的结果,是对互联网大规模分布式系统的实践总结,强调可用性。
理论的核心思想就是:基本可用(Basically Available)和最终一致性(Eventually consistent)。虽然无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
4.实现分布式事务一致性(Consistency)的方法有哪些?
最著名的就是二阶段提交协议、三阶段提交协议和Paxos算法。
两阶段提交协议
- prepare(准备阶段)
当开始事务调用的时候,事务处理器向事务执行者(有可能是数据库本身支持)发出命令,事务执行者进行prepare操作。 当所有事务执行者都完成了prepare操作,就进行下一步行为。 如果有一个事务执行者在执行prepare的时候失败了,那么通知事务处理器,事务处理器再通知所有的事务执行者执行回滚操作。
- commit(提交阶段)
当所有事务执行者都prepare成功以后,事务处理器会再次发送commit请求给事务执行者,所有事务执行者进行commit处理。 当所有commit处理都成功了,那么事务执行结束。 如果有一个事务执行者的commit处理不成功,这个时候就要通知事务处理器,事务处理器通知所有的事务执行者执行回滚(abort)操作。 但是两阶段提交的诟病就是在于性能问题。比如由于执行链比较长,锁定资源的时间也变长了。所以在高性能的系统中都会避免使用二阶段提交。
分布式锁
什么是分布式锁?为什么用分布式锁?
锁在程序中的作用就是同步工具,保证共享资源在同一时刻只能被一个线程访问,Java中的锁我们都很熟悉了,像synchronized 、Lock都是我们经常使用的,但是Java的锁只能保证单机的时候有效,分布式集群环境就无能为力了,这个时候我们就需要用到分布式锁。
分布式锁,顾名思义,就是分布式项目开发中用到的锁,可以用来控制分布式系统之间��同步访问共享资源。
思路是:在整个系统提供一个全局、唯一 的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。至于这个“东西”,可以是Redis、Zookeeper,也可以是数据库。
一般来说,分布式锁需要满足的特性有这么几点:
1、互斥性:在任何时刻,对于同一条数据,只有一台应用可以获取到分布式锁;
2、高可用性:在分布式场景下,一小部分服务器宕机不影响正常使用,这种情况就需要将提供分布式锁的服务以集群的方式部署;
3、防止锁超时:如果客户端没有主动释放锁,服务器会在一段时间之后自动释放锁,防止客户端宕机或者网络不可达时产生死锁;
4、独占性:加锁解锁必须由同一台服务器进行,也就是锁的持有者才可以释放锁,不能出现你加的锁,别人给你解锁了。
常见的分布式锁有哪些解决方案?
实现分布式锁目前有三种流行方案,即基于关系型数据库、Redis、ZooKeeper 的方案
1、基于关系型数据库,如MySQL 基于关系型数据库实现分布式锁,是依赖数据库的唯一性来实现资源锁定,比如主键和唯一索引等。
缺点:
- 这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
- 这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
- 这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
- 这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
2、基于Redis实现
优点:
Redis 锁实现简单,理解逻辑简单,性能好,可以支撑高并发的获取、释放锁操作。
缺点:
- Redis 容易单点故障,集群部署,并不是强一致性的,锁的不够健壮;
- key 的过期时间设置多少不明确,只能根据实际情况调整;
- 需要自己不断去尝试获取锁,比较消耗性能。
3、基于zookeeper
优点:
zookeeper 天生设计定位就是分布式协调,强一致性,锁很健壮。如果获取不到锁,只需要添加一个监听器就可以了,不用一直轮询,性能消耗较小。
缺点:
在高请求高并发下,系统疯狂的加锁释放锁,最后 zk 承受不住这么大的压力可能会存在宕机的风险。
了解RedLock吗?
Redlock 是一种算法,Redlock也就是 Redis Distributed Lock,可用实现多节点Redis的分布式锁。
RedLock官方推荐,Redisson完成了对Redlock算法封装。
此种方式具有以下特性:
- 互斥访问:即永远只有一个 client 能拿到锁
- 避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使锁定资源的服务崩溃或者分区,仍然能释放锁。
- 容错性:只要大部分 Redis 节点存活(一半以上),就可以正常提供服务
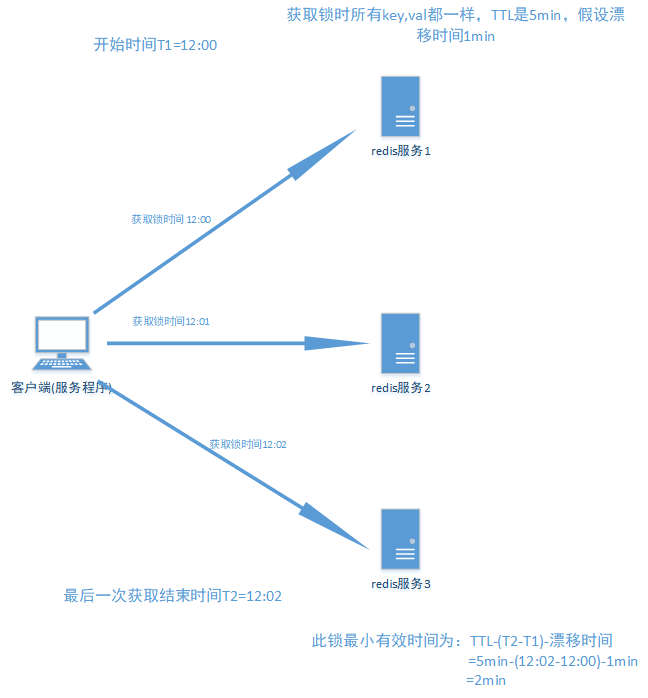
RedLock的原理
假设有5个完全独立的Redis主服务器
-
获取当前时间戳
-
client尝试按照顺序使用相同的key,value获取所有Redis服务的锁,在获取锁的过程中的获取时间比锁过期时间短很多,这是为了不要过长时间等待已经关闭的Redis服务。并且试着获取下一个Redis实例。
比如:TTL为5s,设置获取锁最多用1s,所以如果一秒内无法获取锁,就放弃获取这个锁,从而尝试获取下个锁
-
client通过获取所有能获取的锁后的时间减去第一步的时间,这个时间差要小于TTL时间并且至少有3个Redis实例成功获取锁,才算真正的获取锁成功
-
如果成功获取锁,则锁的真正有效时间是 TTL减去第三步的时间差 的时间;比如:TTL 是5s,获取所有锁用了2s,则真正锁有效时间为3s( 其实应该再减去时钟漂移);
-
如果客户端由于某些原因获取锁失败,便会开始解锁所有Redis实例;因为可能已经获取了小于3个锁,必须释放,否则影响其他client获取锁
算法示意图如下:
分布式锁的实现
- 加锁:
setnx key value - 解锁:
del key - 锁超时:
expire key timeout
问题1:通过 setnx lock1 1 + expire lock1 300 来实现分布式锁的问题
setnx + expire 不是原子性的。如果 setnx 设置成功,但是在执行到 expire 命令的时候因为网络等问题,导致 expire
命令执行失败。 会导致锁没有超时时间,有可能变成死锁。
解决方案:使用 lua 脚本。因为 redis 是单线程的,在执行时不会有其他线程干扰;在执行 lua 脚本时,Redis 不会执行其他客户端的任何命令。
if (redis.call('setnx', KEYS[1], ARGV[1]) < 1)
then return 0;
end;
redis.call('expire', KEYS[1], tonumber(ARGV[2]));
return 1;
// 使用实例
EVAL "if (redis.call('setnx',KEYS[1],ARGV[1]) < 1) then return 0; end; redis.call('expire',KEYS[1],tonumber(ARGV[2])); return 1;" 1 key value 100
问题2:锁误解除
A线程加锁,超时时间为 30 秒,30 秒之后,自动释放锁,但是 A 线程还没执行完, 到 40 秒的时候,A 线程执行完了,执行 del key
命令释放锁,会导致线程 B 获取到的锁被线程 A 释放掉。
解决方案:在 value 中加一个当前线程的标识,在删除之前判断下 value 是否是当前线程持有的。
// 加锁
String uuid = UUID.randomUUID().toString().replaceAll("-","");
SET key uuid NX EX 30
// 解锁
if (redis.call('get', KEYS[1]) == ARGV[1])
then return redis.call('del', KEYS[1])
else return 0
end
问题3:超时解锁导致并发
线程A 获取锁,设置超时时间为 30 秒�,30 秒之后,锁释放,线程 B 获取到锁,此时 线程 A 和线程 B 并发执行。
解决方案:
- 将锁过期时间设置足够长,确保代码逻辑在锁释放前执行完。
- 为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间。
问题4:不可重入
线程 A 获取到锁时,线程 B 无法获取到锁。
解决方案:将 value 加 1
// 如果 lock_key 不存在
if (redis.call('exists', KEYS[1]) == 0)
then
// 设置 lock_key 线程标识 1 进行加锁
redis.call('hset', KEYS[1], ARGV[2], 1);
// 设置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
// 如果 lock_key 存在且线程标识是当��前欲加锁的线程标识
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
// 自增
then redis.call('hincrby', KEYS[1], ARGV[2], 1);
// 重置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
// 如果加锁失败,返回锁剩余时间
return redis.call('pttl', KEYS[1]);
问题5:无法等待锁释放
线程 A 获取到锁时,线程 B 在申请锁时发现锁已经被其他线程获取,此时线程 B 无法等待线程 A 释放锁。
解决方案:
- 线程 B 获取不到锁,就轮询
- Redis 的发布订阅功能,获取锁失败时,订阅锁释放消息,当锁成功释放时,发送锁释放消息。
问题6:主备切换
在主节点上加锁,还未同步到从节点时,主节点挂了
问题7:集群脑裂
集群因网络问题,出现了多个主节点,导致有多个分布式锁。