微服务的九大特性
微服务和核心是无状态化的。
启动一个新的微服务实例应该时简单的,快速的。如果不能满足这个要求,就表示你的设计有问题。
- 服务组件化
- 按业务组织团队
- 做“产品”的态度
- 智能端点与哑管道
- 去中心化治理
- 去中心化管理数据
- 基础设施自动化
- 容错设计
- 演进式设计
Spring Cloud 的主要功能
- 配置管理 spring cloud config
- 服务治理 spring cloud eureka
- 断路器 spring cloud hystrix
- 智能路由 Spring Cloud Ribbon、LoadBalance
- 微代理
- 控制总线 spring cloud bus
- 全局锁
- 决策竞选
- 分布式会话
- 集群状态管理

Spring Cloud Netflix
Service Discovery (Eureka) 服务发现 Circuit Breaker (Hystrix) 断路器 Intelligent Routing (Zuul) 智能路由 Client Side Load Balancing (Ribbon) 客户端负载均衡
一、服务治理
1.1、什么是服务治理呢?
个人理解为就是“服务的管理”。治理的对象就是微服务的实例。
为什么需要治理服务呢? 是因为微服务系统中,实例可能成百上千,难以维护。
目前服务治理的框架和产品都围绕着服务注册与服务发现机制来完成对微服务实例的自动化管理。
服务注册--服务如何使用服务发现代理进行注册。 客户端查找服务地址--服务客户端如何查找服务信息。 信息共享--节点如何共享服务信息 健康监测--服务如何将它们的健康信息传回服务发现代理。
服务注册
每个服务向注册中心提供自己的信息。
服务发现
服�务发现对于微服务和基于云的应用程序至关重要
- 水平扩展或横向扩展--添加更多服务实例和更多容器
- 弹性--在不影响业务的情况下吸收架构或服务中问题的影响
服务调用方向注册中心咨询服务提供方的地址信息。
1.2、Spring Cloud Eureka 服务发现
Netfilx Eureka 是一款基于 REST 的服务发现组件,包括 Eureka Server 和 Eureka Client 。
- 构建服务注册中心
- 服务注册和服务发现
- Eureka 的基础架构
- Eureka 的服务治理机制
- Eureka 的配置
1.2.1、Netflix Eureka
- Eureka 服务端 (注册中心)
- 支持高可用配置(eureka 服务端的集群)
- 分片故障时可自动转为维护模式
- 不同区域的注册中心通过异步模式互相复制各自的状态(replicate)
- Eureka 客户端(服务的注册和发现)
- 向注册中心注册自己提供的服务(register)
- 周期性的发送心跳和更新服务租约(renew)
- 从服务端查询服务信息,并在本地缓存(fetch-register)
优点:
- 能够查找与服务端进行�通信
- 不用硬编码 hostname 和 port,可以直接根据服务名来调用服务。
1.2.2、三个核心要素
- 服务注册中心(eureka server)
- 失效剔除
- 自我保护
- 服务提供者(eureka client)
- 服务注册 register
- 服务同步 replicate
- 服务续约 renew
com.netflix.discovery.DiscoveryClient#renew
- 服务消费者(eureka client)
- 获取服务 fetch-register
com.netflix.discovery.DiscoveryClient#refreshRegistry - 服务调用 通过 ribbon 进行调用
- 服务下线 down
- 获取服务 fetch-register
很多情况下,客户端即使服务提供者也是服务消费者。

1.2.3、Eureka 中 region 和 zone 的区别
region:理解为地区,例如亚洲地区,华中地区等。 zone:理解为 region 中的具体机房。
region 与 zone 的对应关系为一对多。即一个地区中可以有多个机房。
eureka 中,一个微服务应用只可以属于一个 region。如果未配置(通过 eureka.cliner.region 配置),则为 default。

1.2.4、为什么会选择 eureka 呢?
1、提供了服务注册和服务发现功能。 2、和 springcloud 无缝集成 3、开源
1.2.5、源码分析
1.2.5.1、EurekaDiscoveryClient
类图
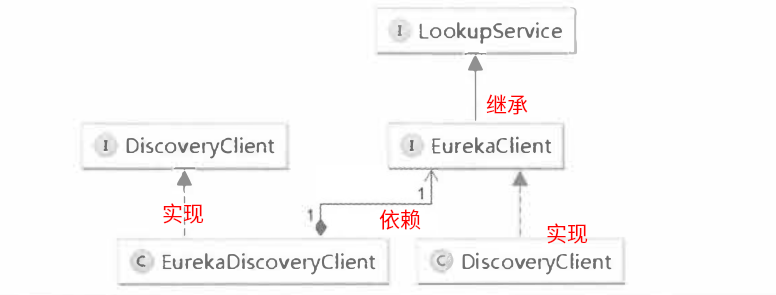
EurekaDiscoveryClient 中有 2 个成员变量,通过构造函数传入。
- EurekaClient 重要的还是 EurekaClient 这个接口的实现类。
- EurekaClientConfig
1.2.5.2、EurekaClient
DiscoveryClient 是 EurekaClient 的实现类。
a) Registering the instance with Eureka Server 注册 b) Renewalof the lease with Eureka Server 续期 c) Cancellation of the lease from Eureka Server during shutdown 下线 d) Querying the list of services/instances registered with Eureka Server 查询注册中心的服务
1.2.5.3、com.netflix.discovery.endpoint.EndpointUtils#getServiceUrlsMapFromConfig
从配置文件中获取注册中心 url 列表。
public static Map<String, List<String>> getServiceUrlsMapFromConfig(EurekaClientConfig clientConfig, String instanceZone, boolean preferSameZone) {
Map<String, List<String>> orderedUrls = new LinkedHashMap<>();
String region = getRegion(clientConfig); // 从配置文件中读取 `eureka.region`,转为小写,默认值为 `us-east-1`
// 从这里可以知道 region 与 zone 是一对多的关系
String[] availZones = clientConfig.getAvailabilityZones(clientConfig.getRegion()); // 根据 region 获取到能够访问的 zone,默认为 `defaultZone`
if (availZones == null || availZones.length == 0) {
availZones = new String[1];
availZones[0] = DEFAULT_ZONE;// 没有配置,则取默认值 defaultZone
}
logger.debug("The availability zone for the given region {} are {}", region, availZones);
int myZoneOffset = getZoneOffset(instanceZone, preferSameZone, availZones);
String zone = availZones[myZoneOffset];
List<String> serviceUrls = clientConfig.getEurekaServerServiceUrls(zone); // 根据 zone 加载注册中心的 url
if (serviceUrls != null) {
orderedUrls.put(zone, serviceUrls);
}
int currentOffset = myZoneOffset == (availZones.length - 1) ? 0 : (myZoneOffset + 1);
while (currentOffset != myZoneOffset) {
zone = availZones[currentOffset];
serviceUrls = clientConfig.getEurekaServerServiceUrls(zone);
if (serviceUrls != null) {
orderedUrls.put(zone, serviceUrls);
}
if (currentOffset == (availZones.length - 1)) {
currentOffset = 0;
} else {
currentOffset++;
}
}
if (orderedUrls.size() < 1) {
throw new IllegalArgumentException("DiscoveryClient: invalid serviceUrl specified!");
}
return orderedUrls;
}
1.3、Spring Cloud Ribbon 客户端负载均衡
Ribbon 是一个基于 HTTP 和 TCP 的客户端负载均衡器。
RibbonServerList 会被 DiscoveryEnableNIWServerList 重写,从注册中心获取列表。
NIWSDiscoveryPing 代替 IPing ,判断服务端是否启动。
- 服务器端负载均衡
- 硬件负载均衡
- 软件负载均衡
- 客户端负载均衡
RestTemplate
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
RestTemplate 为什么能实现负载均衡呢?
在 org.springframework.cloud.client.loadbalancer.LoadBalancerAutoConfiguration 类中,对每一个被 @LoadBalanced 标记过的
RestTemplate 添加了一个 LoadBalancerInterceptor 拦截器。
在 LoadBalancerInterceptor 中的 intercept 方法中的 loadBalancer 的实现类RibbonLoadBalancerClient 的 execute
方法中,使用了 ServiceRequestWrapper (重写了 getURI 方法) 对 request 进行包装。
@Bean
public SmartInitializingSingleton loadBalancedRestTemplateInitializerDeprecated(
final ObjectProvider<List<RestTemplateCustomizer>> restTemplateCustomizers) {
return new SmartInitializingSingleton() {
@Override
public void afterSingletonsInstantiated() {
restTemplateCustomizers.ifAvailable(new Consumer<List<RestTemplateCustomizer>>() {
@Override
public void accept(List<RestTemplateCustomizer> customizers) {
for (RestTemplate restTemplate : LoadBalancerAutoConfiguration.this.restTemplates) {
for (RestTemplateCustomizer customizer : customizers) {
customizer.customize(restTemplate);
}
}
}
});
}
};
}
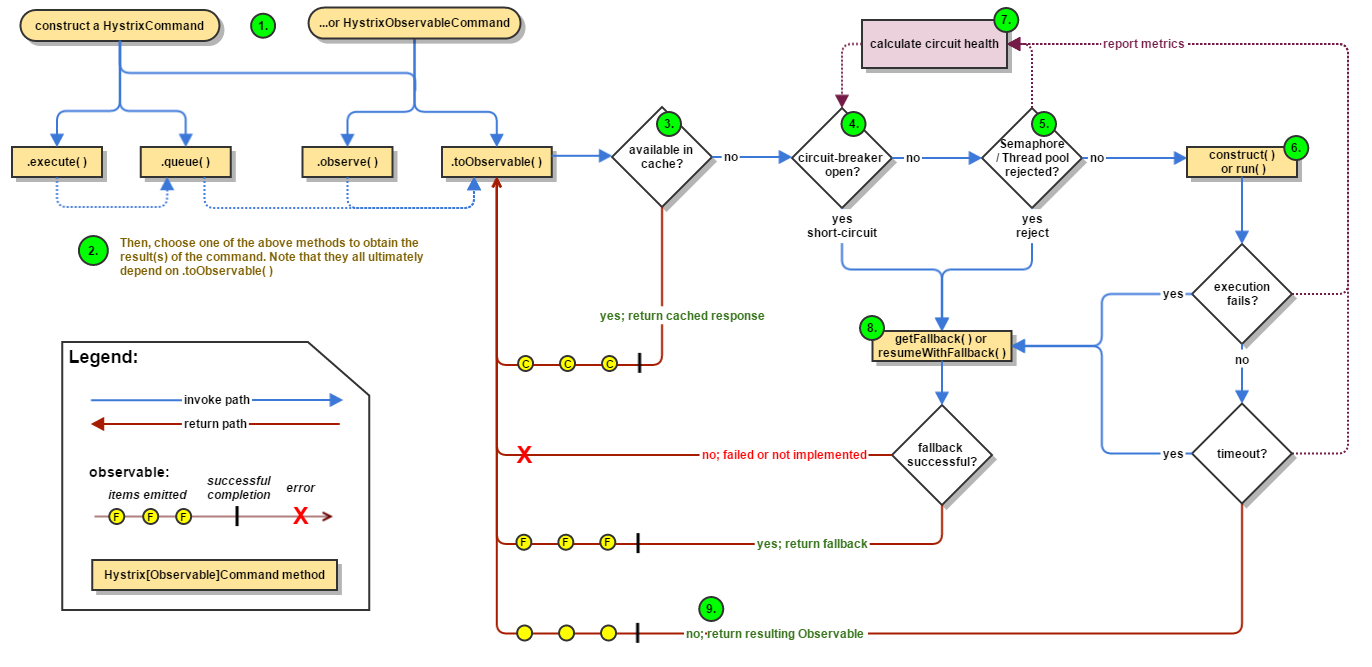
Hystrix
错误1
错误提示:
Command type literal pos: unknown; Fallback type literal pos: unknown
问题原因:
@HystrixCommand(fallbackMethod = "error") 中的 fallbackMethod 方法参数和返回值需要与被修饰的方法保持一致。
流程图
dashboard
management:
endpoints:
web:
exposure:
include: hystrix.stream
hystrix:
dashboard:
proxy-stream-allow-list: "*"
访问:http://{IP}:{PORT}/hystrix 在输入框中输入 http://{IP}:{PORT}/actuatot/hystrix.stream

Spring CLoud OpenFeign
声明式 Web 服务客户端定义方式
API 网关中间件
- 统一接入功能:提供一个高性能、高并发、高可靠的网关服务。还要支持负载均衡、容灾切换和异地多活。
- 协议适配功能:对外请求 HTTP、HTTP2 协议。开发出去的接口 REST、RPC
- 流量管控功能:流量管控、流量调拨,熔断和服务降级。异地多活中对流量分布,路由到不同的机房。
- 安全防护功能:对所有请求进行安全防护过滤,保护后端服务。对 IP 黑名单和URL 黑名单封禁,做风控防刷,防恶意攻击等。
Spring Cloud Zuul
facade 模式
对每一个请求分配一个线程来处理。
根据配置的路由规则或者默认的路由规则进行路由转发和负载均衡。
- 集成 Hystrix 在网关层面实现降级的功能。
- 集成 Ribbon 使得整个架构具备弹性伸缩能力。
- 集成 Archaius 可以进行配置管理等。
- 自定义 Filter 实现 灰度、降级、标签路由、限流、WAF 封禁等。
Spring Cloud Gateway
Spring Cloud Gateway 解决的问题
- 静态路由
- 动态路由
- 验证和授权
- 度量数据收集和日志记录
- 负载均衡
- 请求限流
- 缓存

网关独立存在并充当我们架构中所有微服务调用的过滤器和路由器。
服务网关作为单个策略执行点 PEP(Policy Enforcement Point),所有的调用都通过服务网关进行路由,然后被路由到最终目的地。
底层基于 Netty 实现。(Netty 的线程模型是多线程 reactor 模型,使用 boss 线程和 worker 线程接收并异步处理请求,具有很强大的高并发处理能力)。
基于 Filter 链的方式提供了网关的基本功能,例如,安全、监控/埋点、限流等。
- Route 路由:路由是网关最基础的部分,路由信息由 ID、目标 URI、一组断言和一组过滤器组成。如果断言 路由为真,则说明请求的 URI 和配置匹配。
- Predicate 断言:Java8 中的断言函数。Spring Cloud Gateway 中的断言函数输入类型是 Spring 5.0 框架中 的 ServerWebExchange。Spring Cloud Gateway 中的断言函数允许开发者去定义匹配来自于 Http Request 中的任何信息,比如请求头和参数等。用来判断请求到底交给哪一个 Gateway Web Handler 处理。
- Filter 过滤器:一个标准的 Spring Web Filter。Spring Cloud Gateway 中的 Filter 分为两种类型,分别是 Gateway Filter 和 Global Filter。过滤器将会对请求和响应进行处理。


<!-- spring cloud gateway 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
路由规则
server:
port: 8080
spring:
application:
name: ruoyi-gateway
cloud:
gateway:
routes:
# 系统模块
- id: ruoyi-system
uri: http://localhost:9201/
predicates:
# 匹配请求路径
- Path=/system/**
# 匹配日期时间之后发生的请求
- After=2021-02-23T14:20:00.000+08:00[Asia/Shanghai]
# 匹配指定名称且其值与正则表达式匹配的cookie
# 测试 curl http://localhost:8080/system/config/1 --cookie "loginname=ruoyi"
- Cookie=loginname, ruoyi
# 匹配具有指定名称的请求头,\d+值匹配正则表达式
- Header=X-Request-Id, \d+
# 匹配主机名的列表
- Host=**.somehost.org,**.anotherhost.org
# 匹配请求methods的参数,它是一个或多个参数
- Method=GET,POST
# 匹配查询参数
- Query=username, abc.
# 匹配IP地址和子网掩码
- RemoteAddr=192.168.10.1/0
# 匹配权重
- Weight=group1, 8
- id: ruoyi-system
uri: http://localhost:9201/
predicates:
- Weight=group1, 2
filters:
- StripPrefix=1
路由配置
websocket
spring:
cloud:
gateway:
routes:
- id: ruoyi-api
uri: ws://localhost:9090/
predicates:
- Path=/api/**
http
spring:
cloud:
gateway:
routes:
- id: ruoyi-api
uri: http://localhost:9090/
predicates:
- Path=/api/**
注册中心配置方式
spring:
cloud:
gateway:
routes:
- id: ruoyi-api
uri: lb://ruoyi-api
predicates:
- Path=/api/**
限流配置
控制 QPS ,达到保护系统的目的。
- 计数器算法
- 漏桶(Leaky Bucket) 算法
- 令牌桶(Token Bucket) 算法
根据 URI 限流
spring:
redis:
host: localhost
port: 6379
password:
cloud:
gateway:
routes:
# 系统模块
- id: ruoyi-system
uri: lb://ruoyi-system
predicates:
- Path=/system/**
filters:
# StripPrefix=1配置,表示网关转发到业务模块时候会自动截取前缀。
- StripPrefix=1
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 1 # 令牌桶每秒填充速率
redis-rate-limiter.burstCapacity: 2 # 令牌桶总容量
key-resolver: "#{@pathKeyResolver}" # 使用 SpEL 表达式按名称引用 bean
import org.springframework.cloud.gateway.filter.ratelimit.KeyResolver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import reactor.core.publisher.Mono;
/**
* 限流规则配置类
*/
@Configuration
public class KeyResolverConfiguration
{
@Bean
public KeyResolver pathKeyResolver()
{
return exchange -> Mono.just(exchange.getRequest().getURI().getPath());
}
}
熔断降级
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
spring:
redis:
host: localhost
port: 6379
password:
cloud:
gateway:
routes:
# 系统模块
- id: ruoyi-system
uri: lb://ruoyi-system
predicates:
- Path=/system/**
filters:
- StripPrefix=1
# 降级配置
- name: Hystrix
args:
name: default
# 降级接口的地址
fallbackUri: 'forward:/fallback'
跨域配置
others

Spring Cloud Gateway 工作流程说明如下:
- 客户端将请求发送到 Spring Cloud Gateway 上。
- Spring Cloud Gateway 通过 Gateway Handler Mapping 找到与请求相匹配的路由,将其发送给 Gateway Web Handler。
- Gateway Web Handler 通过指定的过滤器链(Filter Chain),将请求转发到实际的服务节点中,执行业务逻辑返回响应结果。
- 过滤器之间用虚线分开是因为过滤器可能会在转发请求之前(pre)或之后(post)执行业务逻辑。
- 过滤器(Filter)可以在请求被转发到服务端前,对请求进行拦截和修改,例如参数校验、权限校验、流量监控、日志输出以及协议转换等。
- 过滤器可以在响应返回客户端之前,对响应进行拦截和再处理,例如修改响应内容或响应头、日志输出、流量监控等。
- 响应原路返回给客户端。
总而言之,客户端发送到 Spring Cloud Gateway 的请求需要通过一定的匹配条件,才能定位到真正的服务节点。在将请求转发到服务进行处理的过程前后(pre 和 post),我们还可以对请求和响应进行一些精细化控制。
Predicate 就是路由的匹配条件,而 Filter 就是对请求和响应进行精细化控制的工具。有了这两个元素,再加上目标 URI,就可以实现一个具体的路由了。
全链路监控中间件
一个前端请求到后端服务应用的过程中��,会经过很多应用系统,并且会留下足迹和相关日志信息。这些信息分布在不同的主机/应用下。不利于问题排查和定位问题发生的根本原因。
收集、汇总并分析日志信息,进行可视化展示和监控告警。
- 定位慢调用:Web 服务(包括Resuful Web 服务)、慢 REST 或 RPC 服务、慢 SQL
- 定位各种错误:4XX、5XX、Service Error
- 定位各种异常
- 展现依赖和拓扑:域拓扑、服务拓扑、trace 拓扑。
- trace 调用链:将端到端的调用,以及附加在这次调用的上下文信息,异常日志信息,每一个调用点的耗时都呈现给用户进行展示。
- 应用告警:根据运维设定的告警规则,扫描指标数据,如违反告警规则,则将告警信息上报到中央告警平台。
未开源:京东 Hydra、阿里 Eagleye 开源:Skywalking 、pinpoint、Spring cloud Sleuth
Spring Cloud Sleuth
分布式服务跟踪
Spring Cloud Bus
消息代理Message Broker
- ActiveMQ
- Kafaka
- RabbitMQ
- AMQP 高级消息协议 Advanced Message Queuing Protocol
- 消息方向
- 消息队列
- 消息路由(点到点、发布-订阅)
- 可靠性
- 安全性
- AMQP 高级消息协议 Advanced Message Queuing Protocol
- RocketMQ spring cloud bus 只支持 rabbitMq 和 kafaka
Rabbit MQ
基本概念:

消息投递到队列的过程

Kafaka
分布式消息系统
基于消息发布-订阅实现的消息系统
- 消息持久化 时间复杂度O(1)
- 高吞吐
- 分布式
- 跨平台
- 实时性
- 伸缩性
Spring Cloud Config
Spring Cloud Stream
构建消息驱动能力的框架
实现缓存解决方案时,要考虑的三个核心问题
- 缓存的数据需要在某一服务的所有实例之间保持一致。 这意味着不能在服务本地缓存数据。
- 不能将数据缓存在托管服务的容器内存中。 因为托管服务的运行时容器通常受到大小限制。
- 在更新或删除数据时,服务应能够识别出状态更改。
同步请求-响应方式来传达状态变化
使用 Redis 来缓存数据。 Redis 是一个分布式的键值存储,可用作数据库、缓存和消息代理。
如果记录被更新或删除,则通过 REST 请求来更新或删除 Redis 中的缓存。
- 服务之间紧密耦合。
- 如果更新 Redis 缓存的接口地址发生了变化,那么需要同步修改记录更新的地方
- 如果有新增加一个消费者,则必须修改服务的代码,才能让它知道需要调用其他的服务以通知数据变更。
使用消息传递在服务之间传达状态更改
消息传递可能是很复杂但很强大。
在服务中使用消息传递需要深谋远虑。
业务本身是异步工作的,所以最终,我们将对业务进行更紧密的建模。
- 当服务B传达状态更改时,它将消息发布到主题中.
- 服务A监视主题中服务B发布的所有消息,并可根据需要使 Redis 缓存数据失效。
优点
- 松耦合
- 在涉及传达状态更改时,两个服务都不知道彼此。
- 当服务B发布状态更改时,它会将消息写入队列。服务A 只知道它得到一条消息,却不知道谁发布了这条消息。
- 持久化
- 队列的存在允许我们保证,即使服务的消费者已经关闭,也可以发生消息。
- 通过将缓存和队列的方式结合在一起,如果服务B关闭,服务A可以优雅降级,因为至少有部分数据将位于其缓存中。有时候,旧数据比没有数据好。
- 可伸缩性
- 消息存储在队列中,所以消息发送者不必等待来自消息消费者的响应。
- 如果从消息队列中读取消息的消费者处理消息的速度不够快,可以启动更多消息消费者。
- 灵活性
- 消息的发生者不知道谁将会消费它。
缺点
- 消息处理语义
- 如果我们正在使用消息传递来执行数据的严格状态转换,那么就需要在设计应用程序时考虑到消息抛出异常或错误按无序方式处理的场景。
- 如果消息失败,是重试处理错误,还是就这么让它失败?
- 如果其中一个客户消息失败,那么如何处理与该客户有关的未来消息?
- 消息可见性
- 消息编排
- 基于消息的应用程序使得通过其业务逻辑进行推理变得更加困难,因为它们的代码不再以简单的块请求-响应模型的线性方式进行处理。
- 调试基于消息的应用程序可能设计多个不同服务的日志,在这些服务中,用户事务可以在不同的时间顺序执行。
Spring Cloud Stream 的组件

发射器 source
发射器是一个 Spring 注解接口,它接受一个普通 Java 对象(POJO),该对象代表要发布的消息。发射器接收消息,然后序列化它并将消息发布到通道。
通道 chanel
通道是队列的一个抽象,它将在消息生产者发布消息或消息消费者消费消息后保留该消息。(发送和接受消息的队列。)
绑定器 binder
与特定消息平台对话的 Spring 代码。绑定器允许我们处理消息,而不必依赖于特定于平台的库和 API 来发布和消费消息。
接收器 sink
在 Spring Cloud Stream 中,服务通过一个接收器从队列中接收消息。接收器监听传入消息的通道,并将消息反序列化为 POJO 对象。从这里开始,消息就可以按照 Spring 业务逻辑来进行处理。
微服务
技术难点:
- 单体拆分为分布式系统后,进程间的通信机制和故障处理措施变得更加复杂。(RPC、RESTful 调用)
- 系统微服务化后,一个看似简单的功能,内部可能需要调用多个服务并操作多个数据库实现,服务调用的分布式事务问题变得非常突出。
- 微服务数量众多,其测试、部署、监控等都变得更加困难。(docker、k8s)
架构演进过程

- 单体阶段(Spring MVC 架构)
表现层、业务层、数据访问层
所有的模块都放在一个 war 包里面。 缺点:
- 一个功能出现问题,可能会导致整个系统的崩溃。(内存泄露、线程爆炸、阻塞、死循环等)
- 从维护的角度上看,程序升级、维护需要制定专门的停机计划,灰度发布、A/B 测试也�相对复杂。
-
SOA阶段
a. 将每个功能模块划分为单独的服务模块。服务之间通过相互依赖或通信机制,来完成相互通信。
- 缺点:这会导致每个服务模块之间耦合非常严重。
b. 加入 ESB 企业服务总线。将消息解释并路由到各个服务模块。因此,各个服务模块只需要与 ESB 进行通信即可。
SOA 的缺点:过于严格的规范定义带来过度的复杂性。举个不恰当的列子,SOA就是一个黄金做的锄头,什么都能干,但是成本会很高。没有微服务轻量化,开箱即用。
- 微服务 microservice
*微服务是一种通过多个小型服务组合来构建单个应用的架构风格,这些服务围绕业务能力而非特定的技术标准来构建。各个服务可以采用不同的编程语言,不同的数据存储技术,运行在不同的进程之中。服务采取轻量级的通信机制和自动化的部署机制实现通信与运维 **。
- 围绕业务能力构建
- 分散治理
- 通过服务来实现独立自治的组件
- 产品化思维
- 数据去中心化
- 强终端弱管道
- 容错性设计
- 演进式设计
- 基础设施自动化
- 后微服务时代 cloud native
从软件层面独力应对微服务架构问题,发展到软、硬一体,合力应对架构问题的时代,此即为“后微服务时代”。
虚拟化技术和容器化技术。
- 无服务时代
中间件
中间件向下屏蔽异构的硬件、软件、网络等计算资源,向上提供应用开发、运行、维护等全生命周期的统一计算环境与管理,属于承上启下的中间连接层,对企业来说有着极其重要的价值。
常见的中间件:
- 服务治理中间件 Dubbo 等 RPC 框架
- 配置中心
- 全链路监控
- 分布式事务
- 分布式定时任务
- 消息中间件
- API 网关
- 熔断器
- 分布式缓存
- 数据库中间件
注册中心:
保护微服务
- OAuth2:一个基于令牌的安全框架。当调用多个服务来满足一个用户的请求时,每个服务都可以对这个用户进行身份认证,而这个用户无须向处理请求的每个服务提供凭证。
- 密码 password
- 客户端凭据 client credential
- 授权码 authorization code
- 隐式 implicit
- keycolak
- 集中身份认证并支持单点登录
- 支持双因子身份认证
- 兼容 LDAP
- 支持自定义密码策略