Test & evaluate
https://platform.claude.com/docs/en/test-and-evaluate
定义 Prompt 的测试标准
什么样的提示词才是一个好提示词?
- 能解决问题(效果要好)
- 稳定,不能时好时坏
- 响应速度越快越好
- 价格越低越好
- 安全性
如何判断某个 Prompt 是否能够用在生产环境?
定义一个 Prompt 的测试标准,根据这个标准对 Prompt 进行测试和评估。
- Specific: 明确定义要实现的目标。(不要用一些让人有歧义或者开放式的词汇/表述)
- Measurable: 采用量化指标或确定的 Qualitative scales
- 量化指标
- 任务特定指标:F1 score,BLEU score, perlexity
- 通用指标: Accuracy 准确率, precision 精确率 , recall 召回率
- 运行指标: 响应时间,正常运行时间
- 量化方法
- A/B 测试
- 用户反馈
- 边缘情况分析:无错误处理的边缘情况百分比
- Qualitative scales
- 李克特量表:"从 1(毫无逻辑)到 5(完全合乎逻辑)评估连贯性"
- 专家评分标准:语言学家根据既定标准评估翻译质量
- 量化指标
- Achievable 可实现性:目标设定应基于行业基准、先期实验、人工智能研究或专业知识。您的成功指标不应超出当前前沿模型能力的可实现范围。
- Relevant: 确保标准与应用程序目的和用户需求相匹配
Claude 给出的常见成功标准
- Task fidelity(任务保真度) 模型在任务上需要达到何种程度的性能表现?
- Consistency (一致性)模型对相似类型输入的响应需要达到何种相似程度?如果用户两次提出相同问题,获得语义相近的答案有多重要?
- Relevance and coherence (相关性与连贯性) 模型在多大程度上直接回应用户的问题或指令?以逻辑清晰、易于理解的方式呈现信息有多重要?
- Tone and style (语气与风格) 模型的输出风格与期望匹配度如何?其语言对目标受众的适用性如何?
- Private preservation(隐私保护) 模型在处理个人或敏感信息方面的成功标准是什么?它能否遵循指示,不使用或分享特定细节?
- Context utilization(上下文利用)模型如何有效利用提供的上下文?它在多大程度上引用并基于其历史信息进行构建?
- Latency (延迟)模型的可接受响应时间是多少?这将取决于您应用程序的实时性要求和用户期望。
- Price(价格) 运行该模型的预算是多少?需考虑每次 API 调用的成本、模型规模以及使用频率等因素。
建立强有力的实证评估
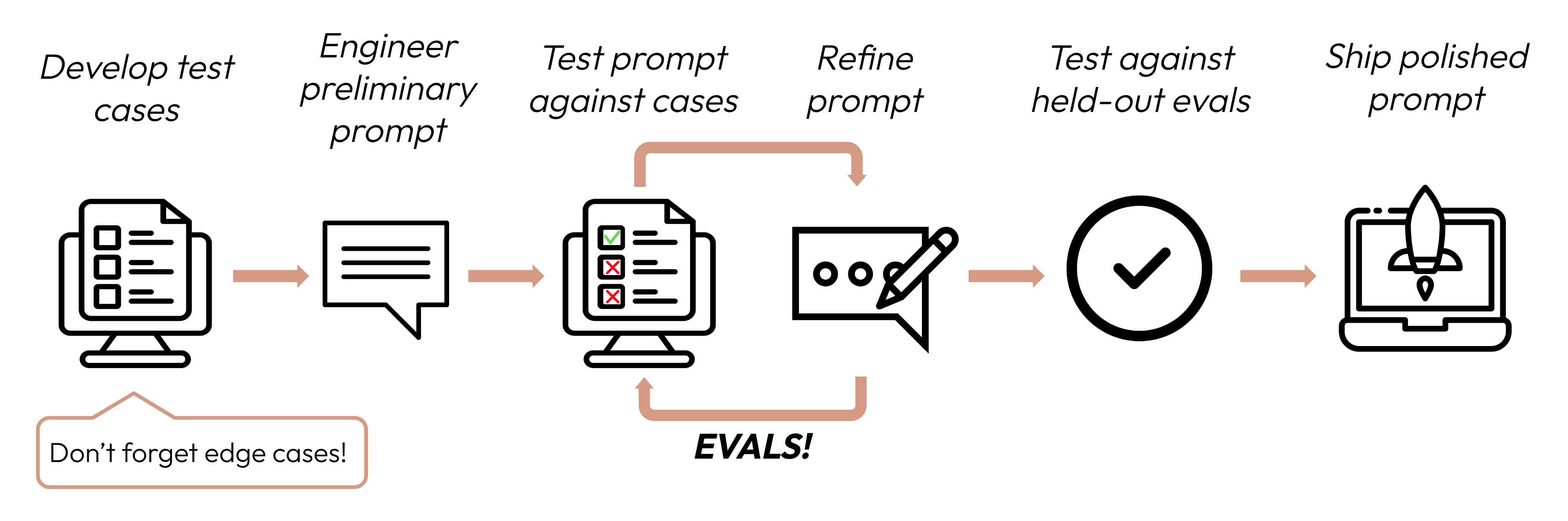
- 任务导向(Prompt 的效果)
- 尽可能自动化(构建支持自动评分的问题结构)
- 优先考虑数量而非质量
降低延迟
一定在先设计一个不受模型或提示限制的提示词,之后再考虑降低延迟。过早尝试减少延迟可能会阻碍您发现最佳性能表现。
延迟的测量指标
- Baseline latency 处理 Prompt 并生成响应所需的时间
- Time of first token 发送 Prompt 到返回第一个 token 所需的时间
降低延迟的方案
- 选择合适的模型
- 优化提示词语输出长度
- 使用流式输出