性能问题
https://space.bilibili.com/472502549/channel/collectiondetail?sid=1954676&spm_id_from=333.788.0.0
1、CPU 偶尔飙高,如何排查?
案例,正则表达式在进行匹配的时候可能会导致 CPU 飙高
方案1:top -H 配合 jstack 这个需要多次执行 jstack 。
方案2:arthas 的 thread -n 1 也要多执行几次。 jad 反编译, watch 查看入参。
2、JVM 发生 OOM 导致不断重启,如何排查?
现象:发现有 hprof 文件,但是下载一半断连了(k8s中止容器了,导致下载不完),使用 MAT 分析时,找到了大对象却定位不到代码。
案例:意外查询大量数据,内存溢出导致进程不响应,k8s kill 导致进程不断重启。
jstat -gcutill $pid 1000定位 GC 问题。ps -o cmd -C java | xargs -n1 | grep -i HeadDumpll -h查看是否有 dump 文件。gzip -c java.hprog > java.hprof.gz先压缩下在下载。1.6G -> 130MMAT内存分析工具进行分析。dominator_tree
- 找
GC Root右键Merge shortest paths to gc roots -> with all references - 若
GC root是线程,查看线程栈Object-> Java Basics -> thread overview and stacks - 展开线程栈,找接口
URL以及查询SQL
问题:如何 GC root 是静态变量应该如何排查?
直接在代码中查看这个静态变量在何处被修改。
x-www-form-urlencode 问题
接口联调时出现问题,尽量从网络包底层来分析。
现象:接口开发者调用接口没问题,其他调用有问�题。
tcpdump 抓包


base64 中 + 变空格
场景:对数据进行 base64 编码,然后手动拼到 url 中,在后台接收数据的时候会出现 + 变成空格的问题。
系统时不时报 GC 耗时高
GC 耗时 2 s 以上,系统流量低
- 分析 GC 日志 (发现有大对象分配)
to-sapce exhaustedG1 在做 gc 时,都是先复制存活对象,再回收原 region,当没有空闲空间复制存活对象时,就会出现to-space exhausted,而这种 GC 场景代价是非常大的。allocation request: 31457294 bytes发现大对象分配
- 定位大对象分配 (定时任务分配大对象)
流量低,ygc 频率低,大对象分配在老年代,用的 jdk8 的 G1 垃圾收集器。 JDK8BUG:在 ygc 不触发的情况下,一直分配大对象不会触发 G1 的 mixGC 回收。
优化GC 参数
G1 回收的过程

G1 在启动 mixed gc 之前需要先执行一个并发周期,且 mixed gc 可同时回收年轻代与老年代。
- 并发周期:它的作用是找到那些垃圾多的 region,并确认对象存活情况。
- mixed gc:从找到的 region 中复制走存活对象,然后回收它,由于 GC 暂停时间和回收内存量正相关,为降低暂停时间,G1 会少量多次地执行 mixed gc
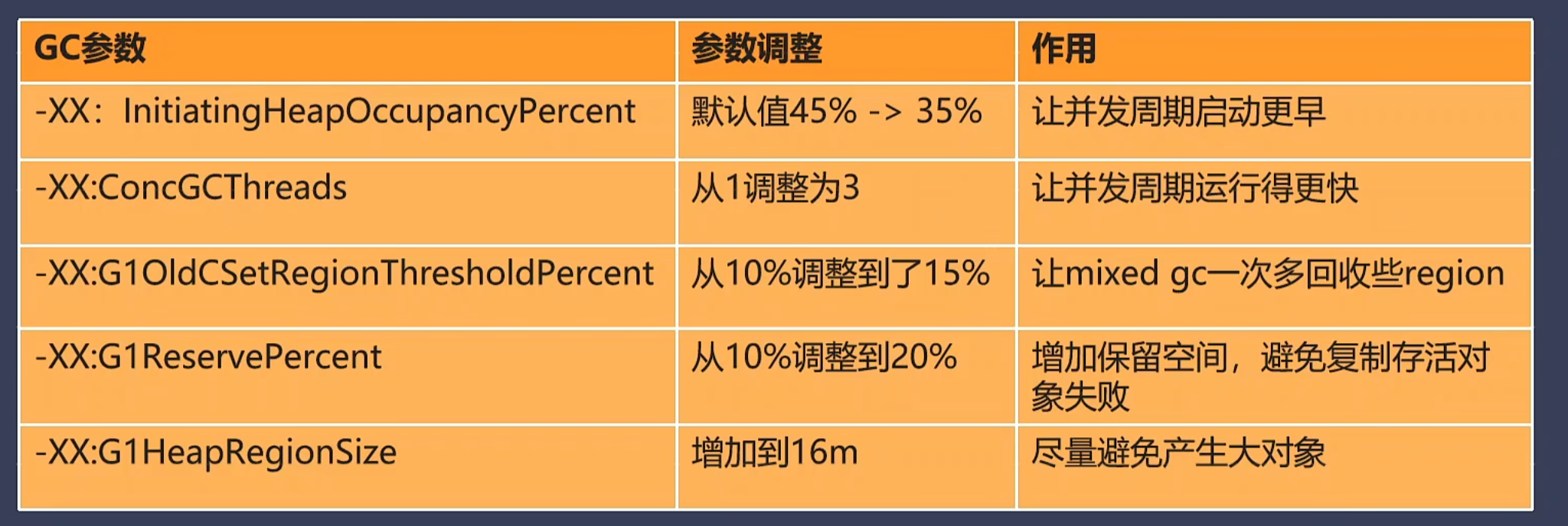
-XX:InitiatingHeapOccupancyPercent 默认值从 45% -> 35% ,让并发周期启动更早 -XX:ConcGCThreads 从 1->3 , 让并发周期运行得更快 -XX:G1OldCSetRegionThresholdPercent, 10%-> 15% ,让 mixed gc 一次多回收些 region -XX:G1ReservePercent 10%->20% 增加保留空间,避免复制存活对象失败 -XX:G1HeapRegionSize 增加到 16m, 尽量避免产生大对象
定位大对象分配位置
开始收集
./profiler.sh start --all-user -e G1ColletedHeap::houmongous_obj_allocate -f ./houmongous.jfr jps
停止收集
./profiler.sh stop -f ./houmongous.jfr jps
分析 jfr 发现,定时任务调用接口返回 14m 的数据,代码中使用 String 来接收,改写成 InputStream 即可解决这个问题。
系统时不时堆内存占用高
现象:堆内存快速飙升至 80% 以上,然后快速回落。
- 分析 GC 日志
- 定位大对象
async-profile��找到分配线程栈(线程栈有可能会失真) - 尝试 gdb,ebpf、perf
- 使用 gdb 看 Java 线程栈,(JV吗 收到 SIGQUIT信号会打印线程栈,使用 gdb 发送此信号)
JVM 内存占用高,但堆内存占用正常
- 检查堆与非堆
- 观察 native 内存块变化 (pmap查看 native 内存块的变化情况)
- 检查 native 内存数据
系统发布时,一波接口超时
- 排查日志代码,检查是否有懒加载的问题
- 编写采集脚本,在服务启动后自动采集 3 次 10s 的火焰图
- 对比火焰图。 (发现大量的类加载操作)
- 预热类加载