索引优化与查询优化
- 索引失效、没有充分利用到索引---索引建立
- 关联查询太多 join(设计缺陷或不得已的需求)---SQL 优化
- 服务器调优及各个参数设置(缓冲、线程数等)---调整 my.cnf
- 数据过多----分库分表
- 物理优化:通过
索引和表连接方式等技术来进行优化。(索引的使用) - 逻辑查询优化:通过
SQL等价变换提升查询效率/
索引失效案例
没有索引
没有索引,就需要对查询的字段创建索引。
SELECT SQL_NO_CACHE * FROM student WHERE age=38;
SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4;
SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4 AND name = 'abcd';
创建索引
CREATE INDEX idx_age oN student(age);
CREATE INDEX idx_age_classid ON student( age , classId);
CREATE INDEX idx_age_classid_name ON student(age,classId , name ) ;
最佳左前缀法则
MySQL可以为多个字段创建索引,一个索引可以包括16个字段。对于多列索引,过滤条件要使用索引必须按照索引建立时的顺序, 依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。如果查询条件中没有使用这些字段中第1个字段时,多列(或联合)索引不会被使用。
主键插入顺序
主键按照从小到大的顺序插入可以减少 页分裂 和 记录位移 等问题。(因为一个页面的数据都是有序的,如果页面满了,然后再向里面插入一条数据,就会出现页分裂的问题)
建议自定义的主键列 id 添加 AUTO_INCREMENT 属性。
计算、函数、类型转换(自动或手动)导致索引失效
CREATE INDEX idx_name ON student(NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%'; -- idx_name 索引生效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc'; -- idx_name 索引失效
CREATE INDEX idx_sno ON student(stuno);
EXPLAIN SELECT SQL_NO_CACHE id,stuno,NAME FROM student WHERE stuno+1 = 900001; -- 索引失效
EXPLAIN SELECT SQL_NO_CACHE id,stuno,NAME FROM student WHERE stuno = 900000; -- 索引生效
类型转换导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123; -- 索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123'; -- 索引生效

范围条件右边的列索引失效
ALTER TABLE student DROP INDEX idx_name;
ALTER TABLE student DROP INDEX idx_age;
ALTER TABLE student DROP INDEX idx_age_classid;
-- CREATE INDEX idx_age_classid_name ON student(age,classId , name ) ;
EXPLAIN
SELECT SQL_NO_CACHE *
FROM student
WHERE student.age = 30 -- 使用索引
AND student.classId > 20 -- 使用索引
AND student.name = 'abc'; -- 索引失效
但并不是所有字段都使用到了索引。 在这里可以看到 key_len 长度为 10 。 因为 name 字段类型为 varchar(20) ; age、classId 字段类为 int 且允许为 null。 如果全部使用到了索引, 那么 key_len 应该为 73 (注:int 类型占用 4 个字节,允许为 null 需要加 1 字节, varchar(20) 占用 20 * 3(utf-8) + 2 + 1 字节) 因此,这个sql 中只有 age 和 classId 字段使用到了索引。

优化建议: 如果这个 sql 出现的很频繁,可以考虑创建
index_age_name_classid(age,name,classId)。 并将sql 修改为下面的 sql(可以不修改,sql 优化器会自动进行优化)
SELECT SQL_NO_CACHE *
FROM student
WHERE student.age = 30
AND student.name = 'abc'
AND student.classId > 20;

不等于( != 或 <> )索引失效
一般情况下, 条件
!=、<>得到的数据太多了,导致回表的次数太多,成本太高,总的成本可能超过全表扫描,因为查询优化器会选择成本较低的查询顺序,即执行全表扫描;

优化建议:尝试使用
=来改写sql。 或者使用索引覆盖(索引中包括要查询的字段select name from student where name <> 'abc';)。

is null 可以使用索引,is not null 无法使用索引
一般情况下, 条件
is not null得到的数据太多了,导致回表的次数太多,成本太高,总的成本可能超过全表扫描,因为查询优化器会选择成本较低的查询顺序,即执行全表扫描;

优化建议: 在设计数据库表的时候,将字段设置为
NOT NULL。
同理:not like 也无法使用索引
like 以通配符 % 开头索引失效。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE 'ab% ';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME NOT LIKE 'ab% ';
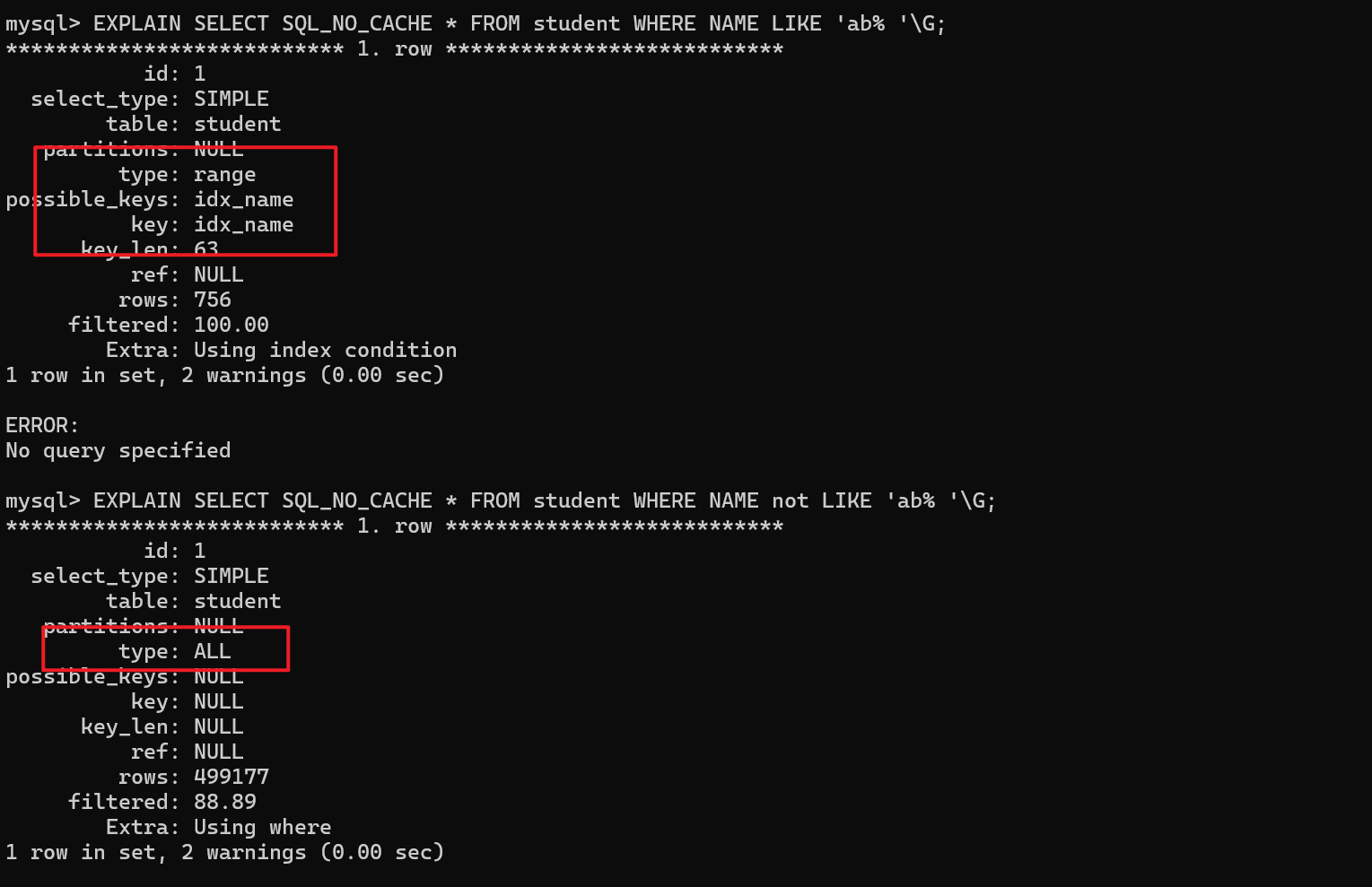
优化建议:页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
or 前后存在非索引的列,索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
age 存在索引,classid 不存在索引。 此时,idx_age 索引失效。

EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR name = 'Abel';
因为 age 字段和 name 字段上都有索引,所以查询中使用了索引。你能看到这里使用到了 index_merge, 简单来说 index_merge 就是对 age 和 name 分别进行了扫描,然后将这两个结果集进行了合并。这样做的好处就是 避免了全表扫描。

OR前后的两个条件中的列都是索引时,查询中才使用索引
数据库和表的字符集统一使用 utf8mb4
不同的字符集进行比较前需要进行转换会造成索引失效。
总结
- 对于单索引列,尽量选择针对当前 query 过滤性更好的索引
- 在选择组合索引的时候,当前 query 中过滤性最好的字段在索引字段顺序中,位置越靠前越好。
- 在选择组合索引的时候,尽量选择能够包含当前 query 中的 where 子句中更多字段的索引。
- 在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面。
关联查询优化
左外连接
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
-- 对连接的字段添加索引
ALTER TABLE `type` ADD INDEX X (card);
ALTER TABLE book ADD INDEX Y ( card);
采用内连接
- 对于内连接来说,查询优化器可以决定谁作为驱动表,谁作为被驱动表出现的
- 对于内连接来讲,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表
- 对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表(小表驱动大表)
join 语句原理
驱动表和被驱动表
驱动表就是主表,被驱动表就是从表。
通过 explain 关键字查看 sql 执行计划,先执行的为驱动表,后执行的为被驱动表。
索引嵌套循环连接

总结
- 整体效率比较: INLJ >BNLJ > SNLJ
- 永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量)(经过过滤条件筛选后,各个表的剩余结果集大小开始比较,表行数 * 每行大小,谁的结果集小谁就是小表)
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=108;#推荐
select t1.b,t2.* from t2 straight.join t1 on (t1.b=t2.b) where t2.id<=108;#不推荐
- 为被驱动表匹配的条件增加索引(减少内层表的循环匹配次数)
- 增大join buffer size的大小(一次缓存的数据越多,那么内层表的扫表次数就越少)
- 减少驱动表不必要的字段查询(字段越少,join buffer所缓存的数据就越多)
- 不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用 JOIN 来代替子查询
- 保证被驱动表的JOIN字段已经创建了索引
- 需要JOIN 的字段,数据类型保持绝对一致。
- LEFT JOIN 时,选择小表作为驱动表, 大表作为被驱动表 。减少外层循环的次数。
- INNER JOIN 时,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表;在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表;在两个表的连接条件都不存在索引的情况下,会选择小表作为驱动表
- 不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用 JOIN 来代替子查询
- 衍生表建不了索引
子查询优化
子查询:一个SELECT查询的结果作为另一个SELECT语句的条件。
子查询是 MySQL 的一项重要的功能,可以帮助我们通过一个 SQL 语句实现比较复杂的查询。但是,子查询的执行效率不高。原因:
① 执行子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
② 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。
③ 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
在MySQL中,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用索引的话,性能就会更好。
尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代
排序优化
为什么要在 order by 字段加上索引呢?
MySQL 支持两种排序方式,分别是 FileSort 和 Index 排序。
- Index 排序中,索引可以保证数据的有序性,不需要再进行排序,效率高。
- FileSort 排序一般在内存进行排序,占用 CPU 较多。如果待排序结果较大,会产生临时文件 I/O 到磁盘进行排序的情况,效率较低。
优化建议:
- SQL 中,可以在 where 和 order by 子句中使用索引,目的时在 where 子句中避免全表扫描,在 order by 子句中避免使用 FileSort 排序。
- 尽量使用 Index 完成 order by 排序。如果 where 和 order by 后面时相同的列据使用单索引列,如果不同就使用联合索引。
- 无法使用 index 时,需要对 file sort 方式进行调优。